
Let’s say you’re getting started in affiliate marketing, but don’t know what’s worth promoting. You just want to find a bunch of programs that you can sign up to in your niche. Great.
Most bloggers concerned with Google use a variant on the following method:
- Block an arbitrary folder from crawl using robots.txt
- Create ‘pretty’ aliases in this folder for ‘ugly’ affiliate URLs. (e.g. “https://ohgm.co.uk/blocked/bluehost” vs “http://bluehost.com?aff=ohgm8858549327234“)
- The blocked folder affiliate URLs are set to 302 redirect to the full ‘ugly’ external affiliate URL.
- Use the pretty links in blog posts with rel=”nofollow”.
We can take advantage of this. Pick another blogger in your niche. Look in their robots.txt for the folder that sticks out like a sore thumb.
Using this information, you can then crawl their site and filter to URLs contained in this subfolder. You now have a complete list of the products they’re promoting. Easy, but time consuming.
Use Google
But we can instead make use of an unfortunate reality:
Internal links blocked by robots.txt, even if never crawled, get indexed. As the affiliate links reside in a single folder, a site:domain.com/folder/ search will reveal all of them.
Turning this on my own site, you can see there are 3 URLs indexed, with two behind the ‘omitted results‘ link:
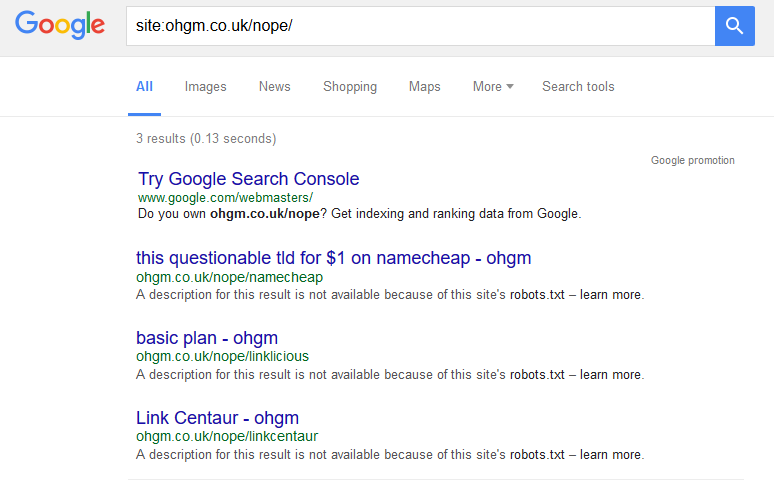
These are indexed despite always having been blocked by a robots.txt rule. Google is using the anchor text as it appears on site combined with sitename for a title, and not the page contents (as the page is simply a redirect).
Note – it may not be an arbitrary subfolder, but a wildcard rule to disallow access to a URL parameter. In this case you can still search Google:
site:domain.com inurl:*?parameter=*
To summarise:
- Find the likely folder.
- Get a list of URLs in this folder using Google.
- Sign up to programs.
Thanks for reading.
Avoiding This
Let’s assume that you’re a blogger and you don’t want all your affiliate efforts this easily listed. What do you do?
If you read my earlier ‘noindex via robots.txt‘ post, you’ll know I’m a mild believer in using the noindex directive in robots.txt to remove URLs you have crawl prohibitions on from the index. I’m not that confident in it, but this seems like a good opportunity to test it out. In short, you can pair up your directory blocked in robots.txt with a disallow rule:
Disallow: /recommends/ Noindex: /recommends/
To test it out on this blog, I added the rule to the /nope/ subfolder in my robots.txt on the 8th June 2016. For a while nothing happened. Checking this on the 28th of June, one had dropped:
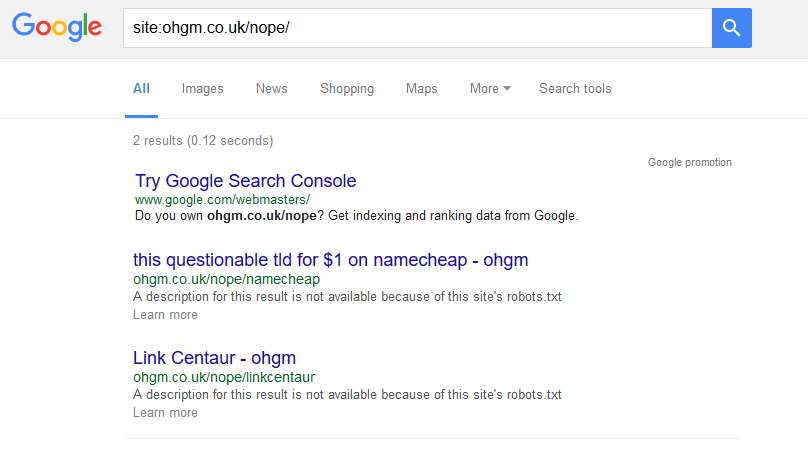
On the 29th, one remained:
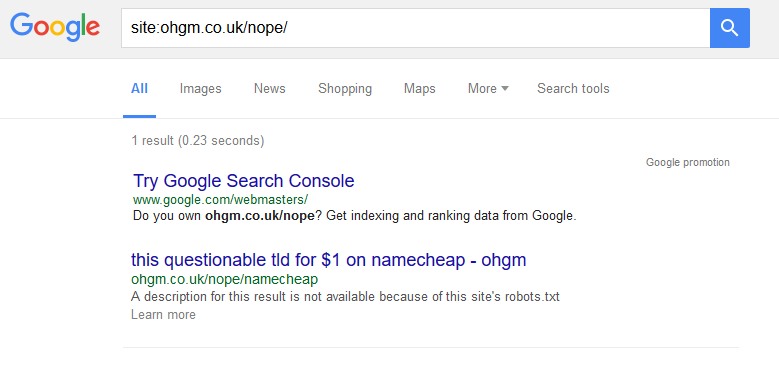
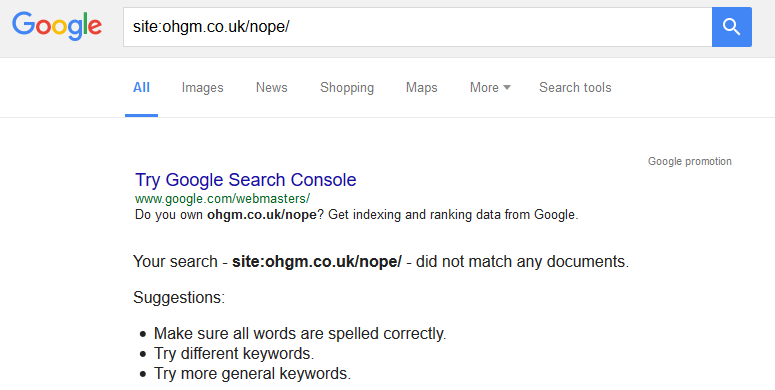
I’ve since been using oldrobot.org to check when some of these restrictions come in on other, larger sites. This tool can be used as a general wayback-machine-diff-checker. It’s good.
Some affiliates have been playing with this method for a while. For example, whoishostingthis implemented it just over a year ago (June 12th 2015).
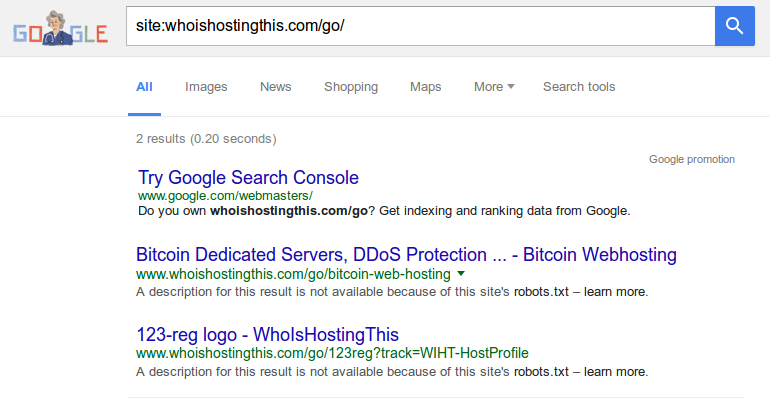
Now only two of these URLs are included in the index. A quick look at the site reveals that the site has just over 200 of these unique offer URLs at crawl. Up to 99% de-indexation would be incredible, but it may be a less impressive case of preventing indexation rather than reversing it.
Vouchercloud (a-not-my-blog-example)
My BrightonSEO drinking partners Vouchercloud were hoping to remove their blocked offer redirects from the index. They applied this method using a wildcard rule to capture the relevant parameter on their Vouchercloud.ie domain (offers resided in separate subfolders rather than a single offer folder):
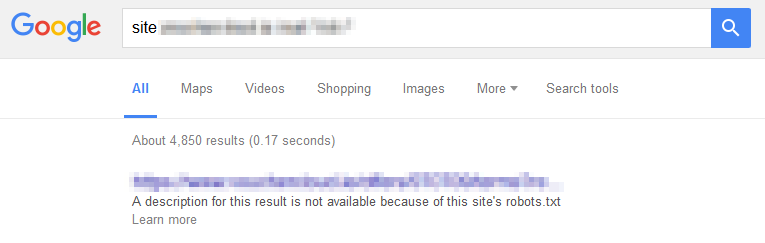
I took the above screenshot shortly after they’d put the rule into place. This is what happened to the ‘About XXXX results‘ figure when I remembered to record it:
- About 4850 June 7th
- About 4830 June 9th
- About 4750 June 13th
- About 4730 June 14th
- About 4710 June 15th
- About 4700 June 16th
- About 4700 June 17th
- About 4690 June 18th
- About 4670 June 19th
- About 4650 June 20th
- About 4610 June 22nd
- About 4590 June 23rd
- About 4580 June 24th
- About 4570 June 28th
- About 4560 June 29th
- About 4330 July 4th
- About 4310 July 5th
Or if you prefer charts:
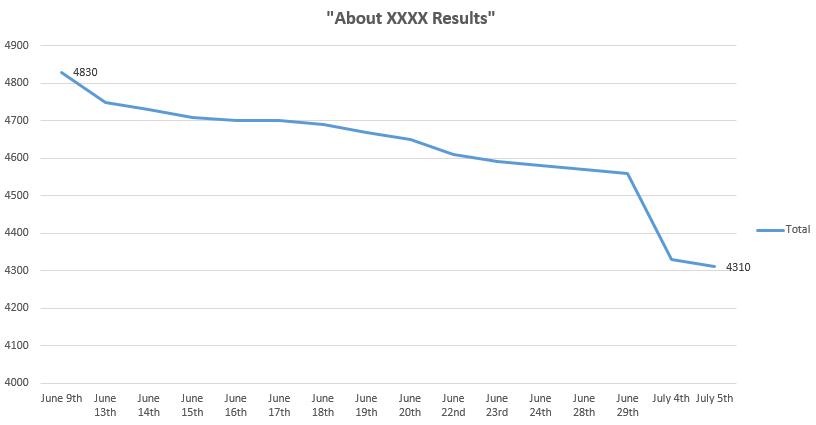
As you’re more likely to be reading this in the future than on the day of publication, you can test this here. I’m guessing it’s fallen further.
Preventing Indexation
The whoishostingthis example above prompted me into another test. Does it prevent indexation of novel URLs? The following link to a blocked resource was added to my ‘hire me please‘ page on June 13th:
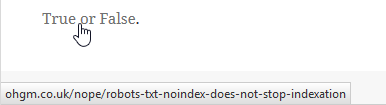
As this is a live test, you can check it out yourself now. If the page ‘robots.txt noindex does not stop indexation‘ appears (is indexed), then you can be pretty sure that robots.txt noindex does not stop indexation.
So far – yes, it prevents indexation.
If this remains true, you should pair up new disallowed parameters with robots.txt noindex rules.
I was sent an update that Vouchercloud had rolled out a new structure for the .com domain. They included the rule to prevent crawl & indexation (here) of novel URLs. This seems to be working so far:
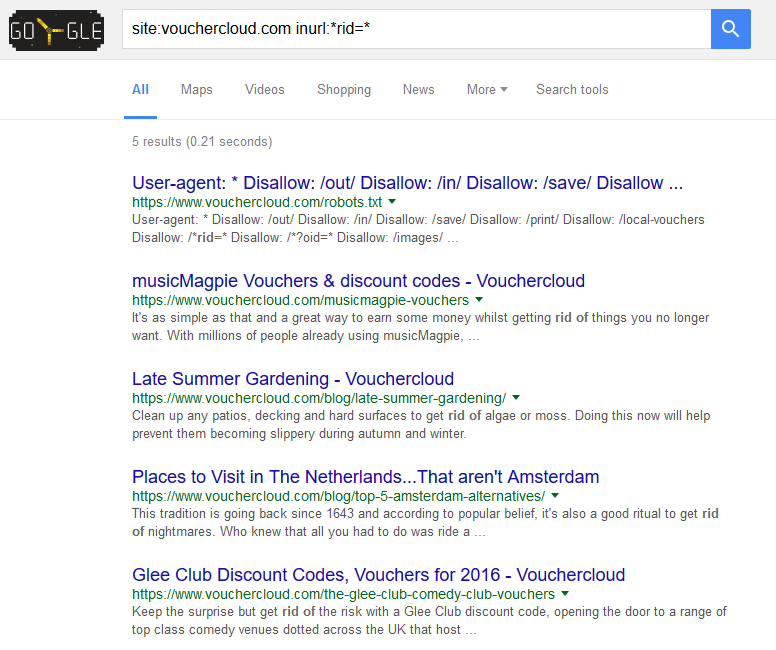
Again, it’s a live test and you can test it here. Please comment if it’s no longer true and blocked offers are appearing in SERPS.
Conclusion
There’s reason to be skeptical regarding the reported indexation figures, but I’m pretty convinced that the robots.txt noindex directive works (very slowly). I also don’t want to wait another ~230 days until they’re all out of the index so I can write about it, so this may be a factor in my attitude. I also think to rate of deindexation will slow further so they’ll never all be out, but it’s nice to have something to revisit.
If we’re still thinking about protecting our affiliate products from being uncovered, I don’t think getting these removed from the index is of any benefit, and it may encourage crawling from the people who aren’t dissuaded by the first hurdle and just want the information. I’m more excited about the possibility of preventing new crawl-restricted structures from appearing in the index at all.
Comment below!
This is awesome! I never knew you could use robots.txt to noindex pages. I recommend using normal noindex though because John Mueller says it’s not recommended.