
Scenario
A client was working on a dynamic XML Sitemap containing potentially juicy information competitors would be very interested in.
During the project, someone raised an objection that this was commercially risky because of how easy it would be for scrapers to find this information.
As is frequently the case on this blog: this is a thought experiment. It is not an idea with serious commercial benefit.
So I asked myself (and some other SEOs) the question from the opposite direction:
"Hi. I'm sure my competitor has an XML Sitemap that they've hidden. I've tried everything. How can I find it?"
This is to give better ideas for how you might frustrate someone attempting to find an XML Sitemap.
Host it on another website
You can have a 3rd party XML Sitemap referenced in robots.txt, and I think it’ll be respected. You can ping an XML Sitemap located anywhere. I have serious doubts that this does anything if the URLs contained within it are hosted on another website (since anyone can ping them).
You can’t reference a 3rd party hosted XML Sitemap in Search Console (which seems absurd to me):
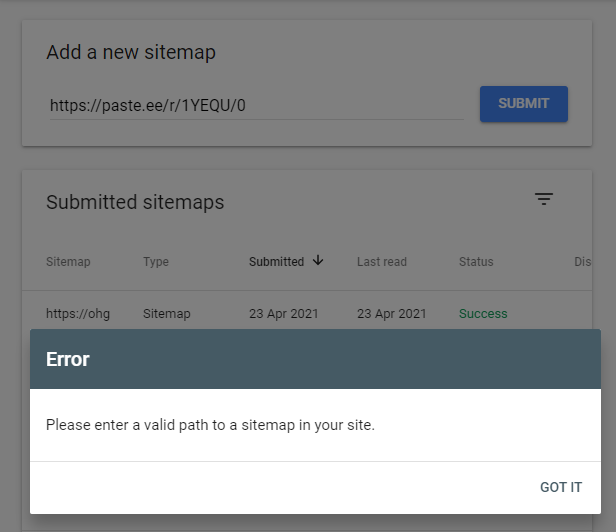
However, Search Console loves to pretend redirects don’t exist, follows them blindly, and reports the result of the destination and not the URL you entered (e.g. you can use the URL Inspection Tool on websites that don’t belong to you.).
But if I set up a redirect, and have the destination of that redirect be a URL on another website, Google Search Console will accept it:
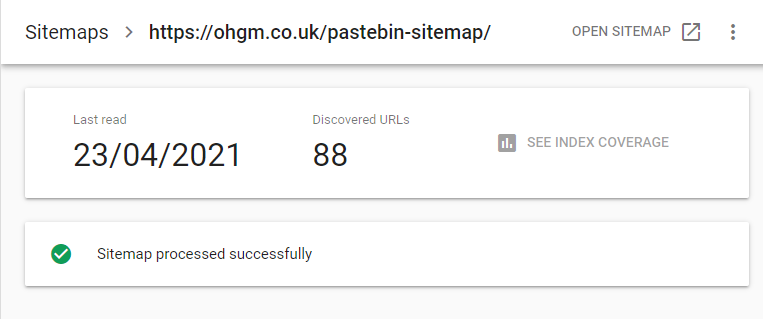
As always, it take a couple of days for the index coverage report to become available:
But then it just works:
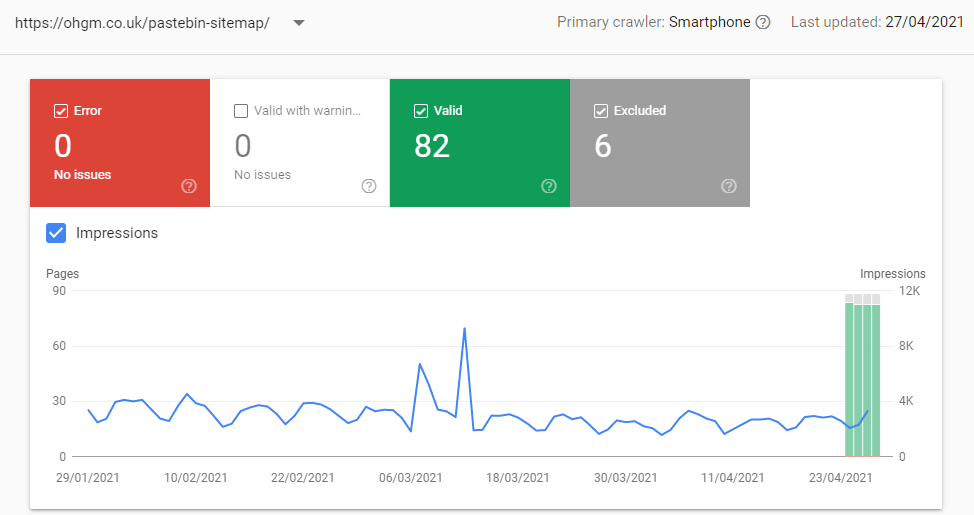
An XML Sitemap on a redirect? If that sounds familiar to you it’s probably because you are remembering Tom Anthony’s post.
One very minor issue with how Google Search Console processes Index Sitemaps is that you need to submit the individual sub XML Sitemap URLs if you want to be able to filter coverage reports by the URLs contained in an individual XML Sitemap.
Non Standard Location
You probably shouldn’t put it on /sitemap.xml.
Not referencing it in robots.txt or an index sitemap
Most search engines have their own webmaster tools or methods for submitting XML Sitemaps, so it should follow that you shouldn’t be including your valuable file here in either robots.txt or an index sitemap.
Noindex
There’s a small risk (especially if they are well formatted and return valid HTML also) that Google will sometimes decide that an XML Sitemap is worth indexing.
If this is the case, then a few creative Google Searches will uncover it.
To avoid this, returning the Sitemap file with a HTTP noindex:
X-Robots-Tag: noindex
This should ensure it won’t show up to Google Dorking e.g.
filetype:xml inurl:sitemap
Cloak it
Return a 404 error on that URL for anything which isn’t verified Googlebot.
An example of this sort of thing would be this website’s robots.txt:
User-agent: * Disallow: / #If noindex comes back, I would like to know Noindex: / #RIP ohgm.co.uk
I would be impressed if you could manage to fall foul of search engine guidelines for this, and what punitive action could even look like.
An interested party could get access to this information if they knew exactly where to look, but it would be tiresome.
Drop the Extension
It seems to be specified as a requirement in Google’s documentation here, but my testing indicates they don’t actually need it. Google can handle it without issue.
Instead of returning the file on ‘filename.xml’, you can return it on ‘filename’. It’s a bit rude to not include an extension, but Google doesn’t need it.
Drop the XML Format
Conversely, you can change to another format. TXT Sitemaps exist also.
"You can name the text file anything you wish, provided it has a .txt extension (for instance, sitemap.txt)." - https://developers.google.com/search/docs/advanced/sitemaps/build-sitemap#text
No-one ever looks for them.
Embrace a Hostile Naming Structure
Fire up a password generator and let rip.
/juicy-1z2x3c4v5b6n7m8l0p9kijhgfsecr5tgnu8-1z2x3c4v5b6n7m8l0p9kijhgfsecr5tgnu8-1z2x3c4v5b6n7m8l0p9kijhgfsecr5tgnu8-speak-to-oliver-this-is-important
You’ll need to make sure the URL can resolve, of course.
Have Decoys
It’s very likely you already have non-juicy publicly accessible information which you feed to search engines, probably for getting feedback on indexing and encouraging canonicalisation.
If you have a comprehensive appearing XML Sitemap in a standard location, referenced in robots.txt, anyone poking around in there may assume that this is all you are submitting to search engines.
Conclusion
I realise that this is security by obscurity and therefore not good.
I am not aiming to make files literally impossible to find, but I am attempting to raise the amount of effort required to where bribing an employee would be significantly easier than trying to find the location through other means.
To reiterate the scenario:
- Competitor does not know this Sitemap exists.
- But if they have a hunch it exists, they’ll look in a standard location. They’ll find XML sitemaps listed in an index sitemaps, but not this one, weakening the hunch.
- If the hunch is rock-solid, then they’ll have to get creative to find the location of the file. As the XML Sitemap is not indexed, they will not be able to use Google Search commands to locate it (on the off chance it was indexed).
- In order to find exactly where it exists, they need to know that they have to somehow get genuine Googlebot to crawl the URL for them, and return the output to them. This is possible with Search Console and redirects, but there account limits which would require some challenging workarounds.
- Any ‘brute force’ style methods will have to work as Genuine Googlebot and not get caught by any other security setup (e.g. DDOS protection).
- Again, the file is named something like – “/why-123-is-754-he-098_like_9328/this-i-justwant–to-watch-n-e-t-f-l-i-xiiat-the-enderderday-andgoh0me_S30-is–not__that__interesting“, and does not have a file extension.
- Or it’s a .txt.
There are no doubt creative ways they could find this, but I think they fall into the “your employee has been bribed” or “they have access to your server logs and/or server” buckets.
Challenge?
Although I’d rather not get completely wrecked, please DM me if you can find the sitemap file on my website which contains only a single URL. I have not been able to find this myself, and would love to know how to do this.
I’d also appreciate if you can comment any other ideas for keeping these hidden, yet accessible, below.
Please limit yourself to Google Search Operators and other obviously legal methods, rather than ruining my life. If there’s an automated way to sniff these out…
This is an old post I didn’t like very much.
There’s very little business value to be gained from it. But it’s also an interesting thought experiment and example of how you might plausibly do something that goes against standard practice.
Thanks to anyone who put up with me asking about this (and sorry for the lack of credit, it was over a year ago).
Nice tricks, especially the redirect
The decoy combined with hostile naming one seems to make a ton of sense. Use one sitemap for public stuff and the other for the sensitive stuff. Great post