
Like many SEOs I’ve been spending some time with the new Search Console. This got me thinking – how trustworthy is the Last Crawled data, and what can it tell us?
Crawl dates in this new version are given down to the second:
If accurate this is (ignoring UI delays) incredible for testing. We’ve never had this level of granularity before. It also allows us to test some long held intuitions.
To start I looked at pages excluded with a noindex tag, and their last crawl dates:
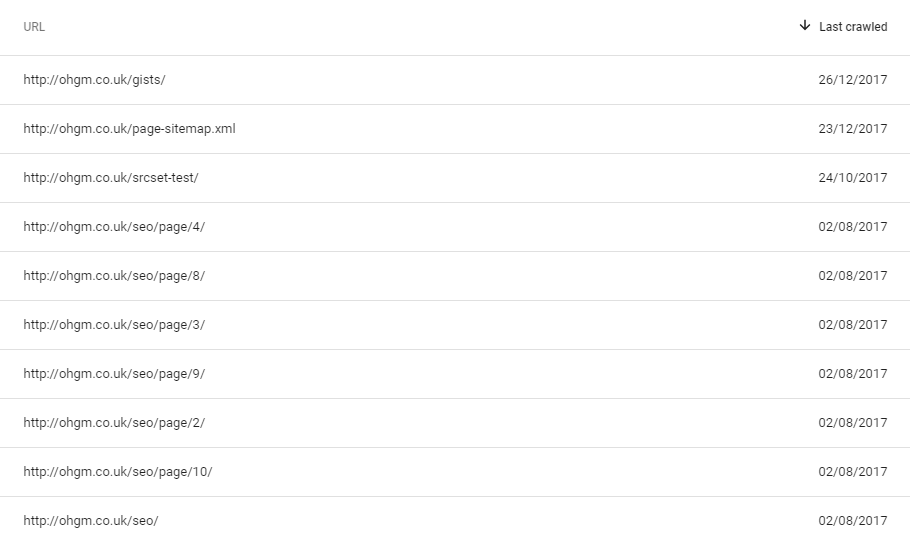
Since all are set to noindex, they aren’t crawled as frequently. Would a Fetch and Render count as crawl for the interface?
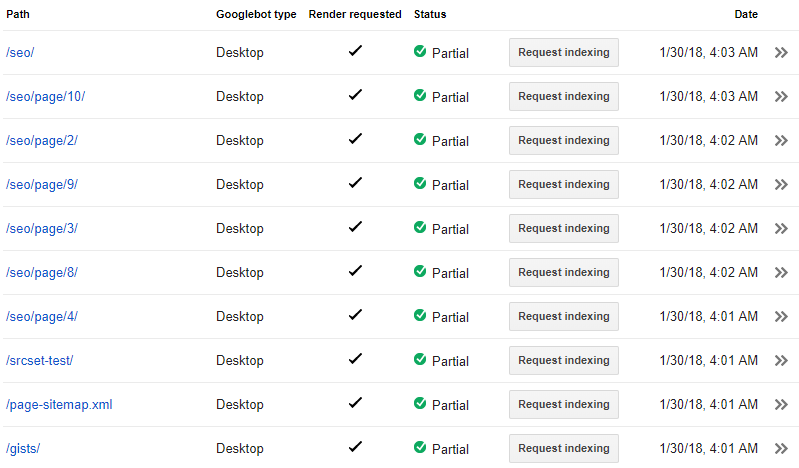
The initial selection and submissions were made on the 30th of January. The reports are updated daily, but using data which may be delayed by up to one week (I’ve not seen consistent behaviour here yet).
If none of the dates change, then we can be sure that Fetch and Render does not count as crawl for Search Console’s purposes. Looking from the 13th of Feb, the Graph goes up to the 10th of Feb. Only a single URL from Fetch and Render submissions has been crawled:
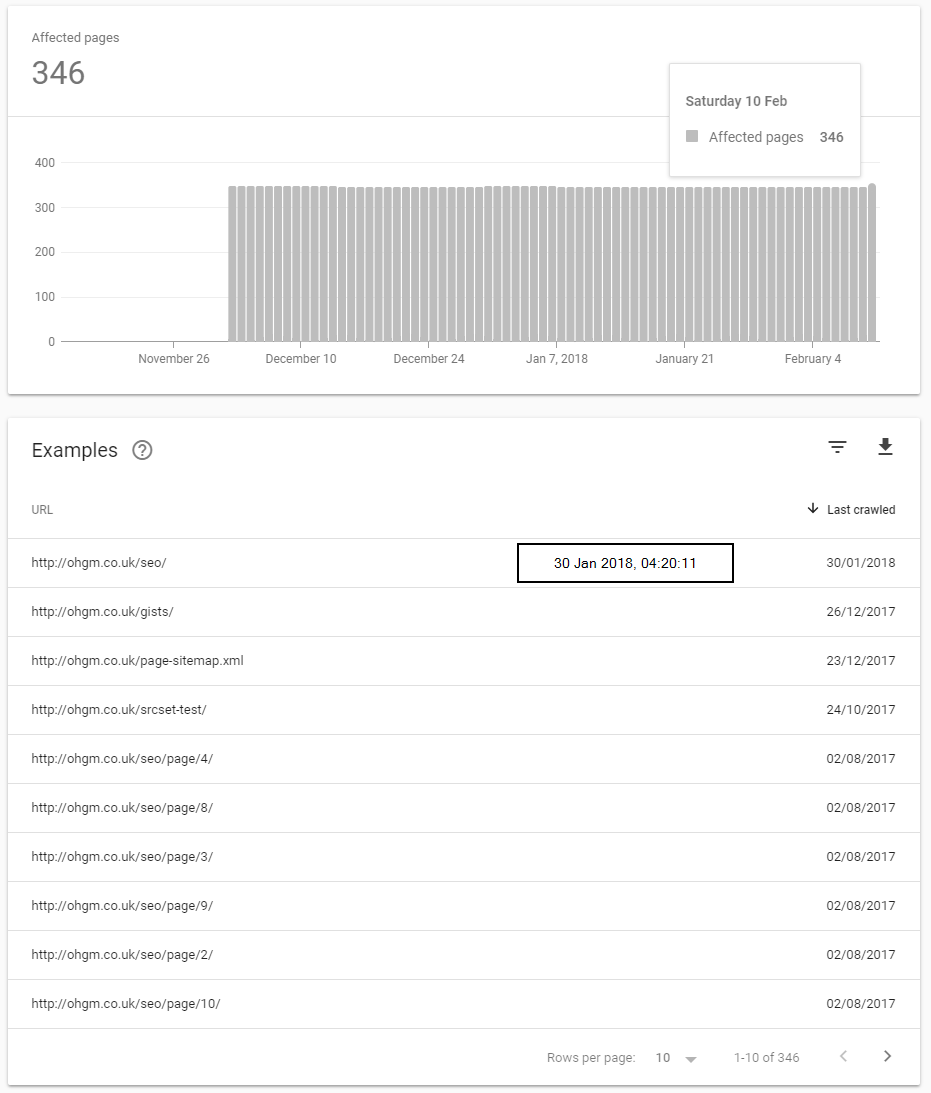
Notice the the crawl timing is 17 mins after submission, and that only the 1st submitted URL was crawled over the two weeks. This may be a coincidence, but I think it’s more likely to be intelligent crawl scheduling tagging these URLs with a tiny positive signal.
Fetch and Render submissions do not count for ‘last crawl dates’ reported in search console, nor do they meaningfully encourage crawl.
But what if we also request indexing?
Crawled Not Currently Indexed Due to Complete Lack of Interest
According to the new Search Console, these are my most terrible posts:
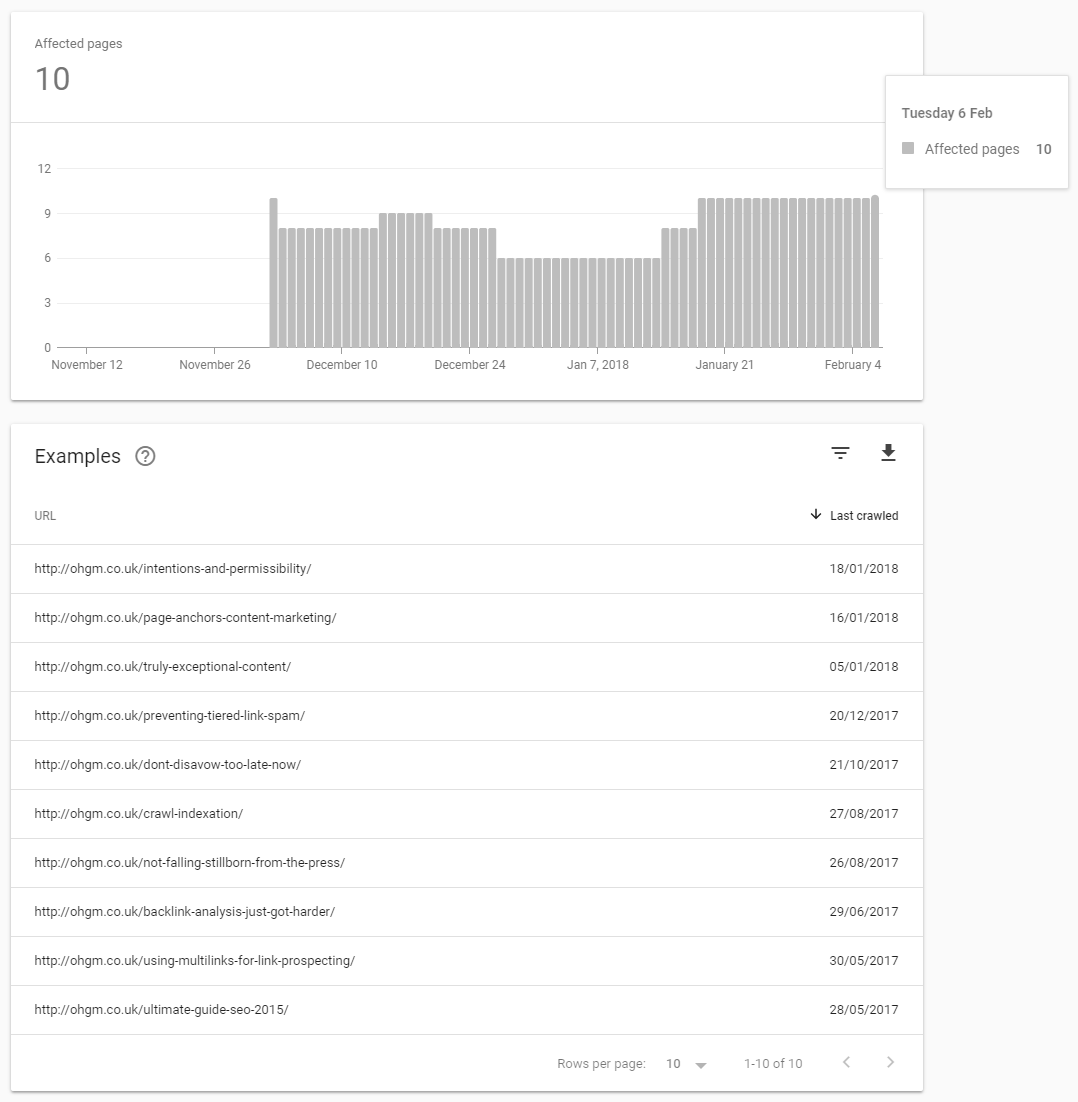
Nothing prevents their appearing in the index but a lack of quality. On Feb 5th I submitted each of these 10 for indexing using Fetch and Render to see if this would trigger ‘crawl’:
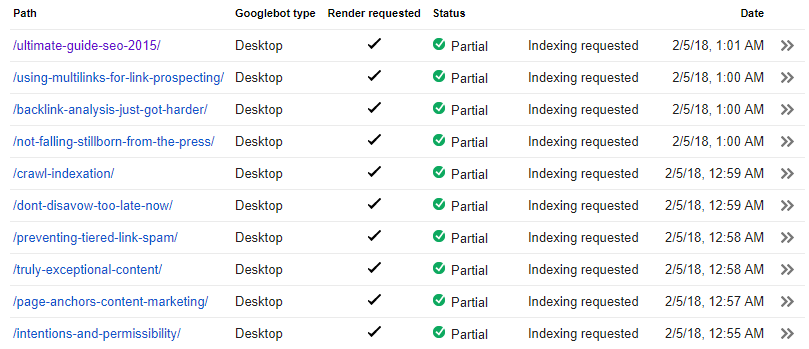
Surprisingly for 6 of the submitted articles, the pages were reported as crawled and indexed:
The old Search Console version’s timestamps are recorded in GMT-8 (the time in Mountain View, CA). The new Search Console interface reports in local time (for me, GMT).
Keeping this in mind, check out the timestamps. Now check out the timestamps on submission:
They do not align with the submission times (even with 8 difference), meaning that they are given to the Scheduler, rather than added to the front of the crawl queue.
Here are the Googlebot requests to ‘intentions-and-permissibility‘ around this period:

The first two requests are fetch and render. The first highlighted request is pictured Fetch and Render request:
12:55AM Mountain View Time = 08:55AM in UK Time.
This logged request aligns perfectly. The next highlighted request 08:57:05 is either just after my submission for indexing (possible), or a crawl they have made of their own volition.
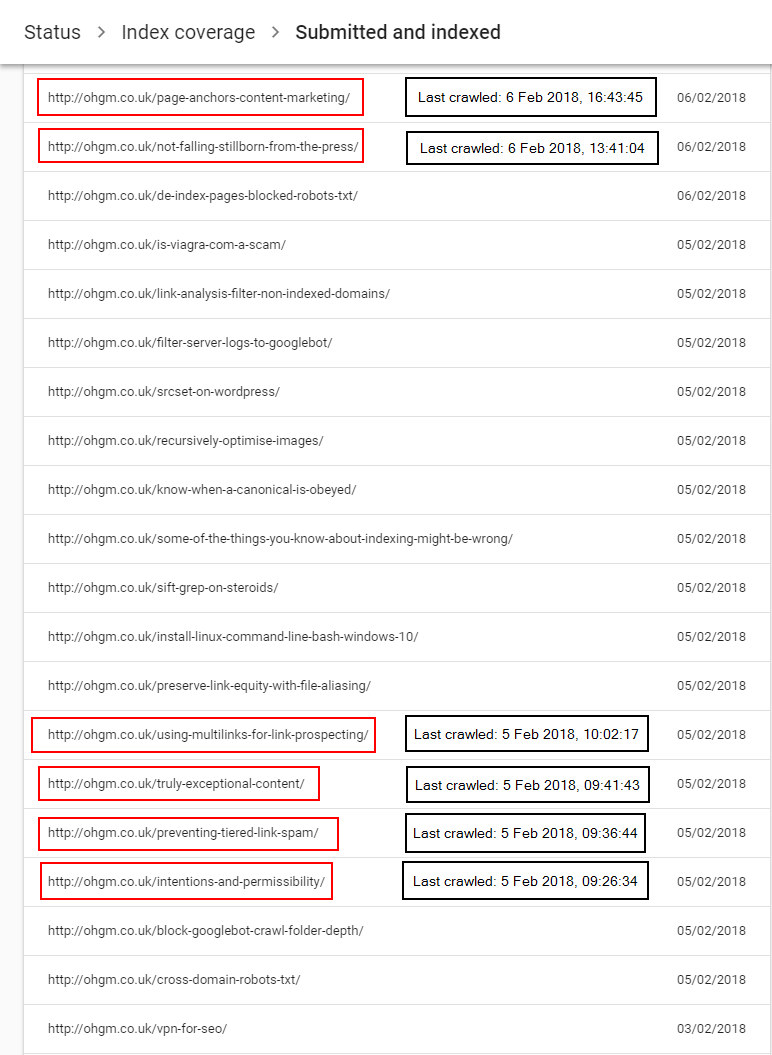
The third highlighted request is the aligns with the ‘last crawl date‘ pictured from the Search Console report:
09:26:34 in Search Console = 09:26:33 in Server Logs
But the final request, 5 mins later and using the smartphone UA is not reported as the last crawled time in search console. Even accounting for a reporting delay (it’s the 13th as I write this), the crawl should have appeared by now.
If I had to guess, this lack of Smartphone Crawl counting as last crawl could be down to ohgm.co.uk not being in the mobile first index (~20% crawl is smartphone). Maybe it is as simple as that. But the new search console is not reporting (for this website at least) mobile crawl data under ‘last crawled’.
Each of the subsequently indexed URLs had additional requests after the first Fetch and Render. This makes some sense. The indexing request made from the interface can be placed significantly later than the initial Fetch & Render request- the ‘request indexing’ button stays in place for a while.
To avoid mischief (e.g. getting Google to index page A, immediately serving page B to users), a second crawl is required. Even URLs which are immediately indexed are done with a second crawl. Google simply can’t trust Fetch and Render data without opening themselves up to our bullshit.
Failed Submissions
Four of the submitted URLs did not get indexed. The crawl dates in Search Console have not updated for the URLs either:
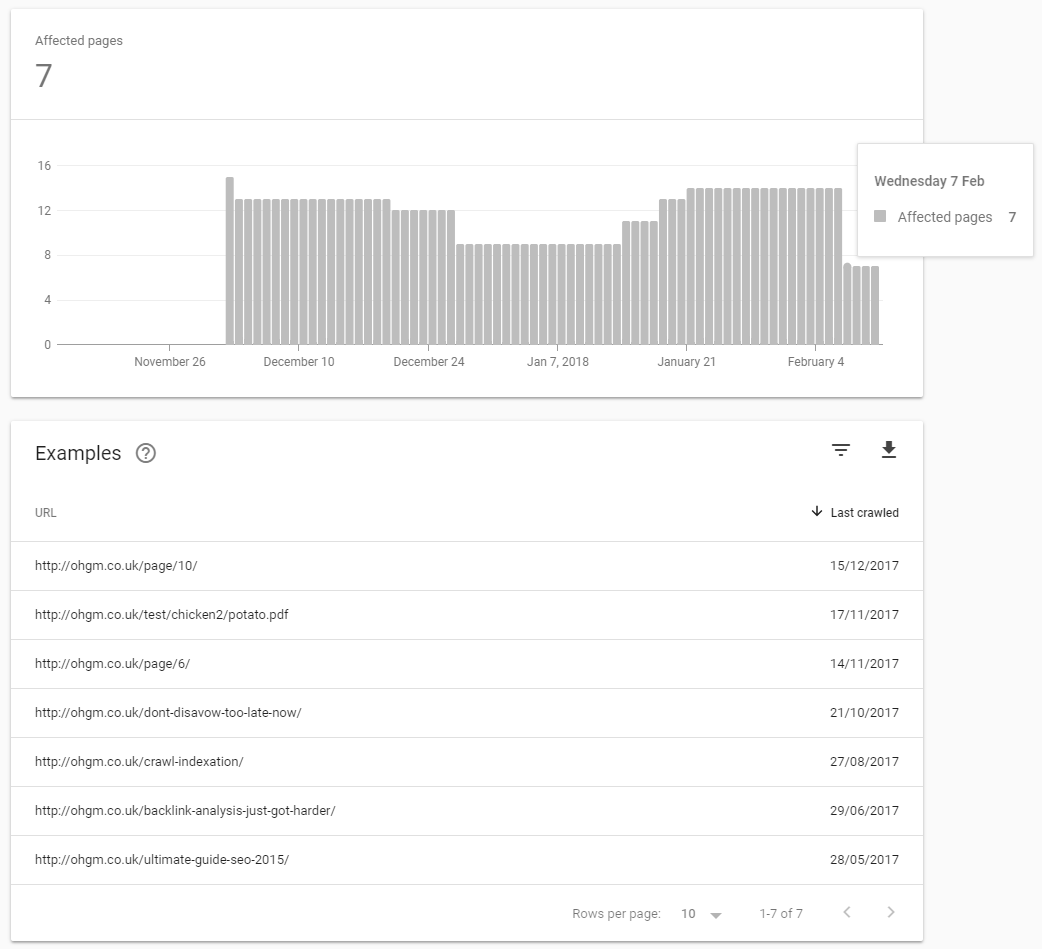
In the server logs the URLs have one request each for the period – which matches The Fetch and Render made in Search Console. And since this submission doesn’t seem to count for indexing purposes, the request must have been ignored, or didn’t amass enough priority to get scheduled in two weeks.
If this is the case, then ‘Request Indexing’ merely adds more priority to a URL in the queue. It’s no guarantee that Google will even properly crawl the thing for reconsideration.
This seems in line with Google’s general approach to Hints and Directives (which are also hints). This isn’t criticism – this is the way things have to be on this scale. But it does indicate that the ‘submit to index’ button really isn’t the panacea many of us take it to be (as I write this there is some Twitter discussion around Google removing the wording around limits to this option).
Requests to URLs Blocked in Robots.txt
Given my predilection for robots.txt, I find this section the most interesting. Check the crawl timings on these indexed pages when sorted by last crawl date:
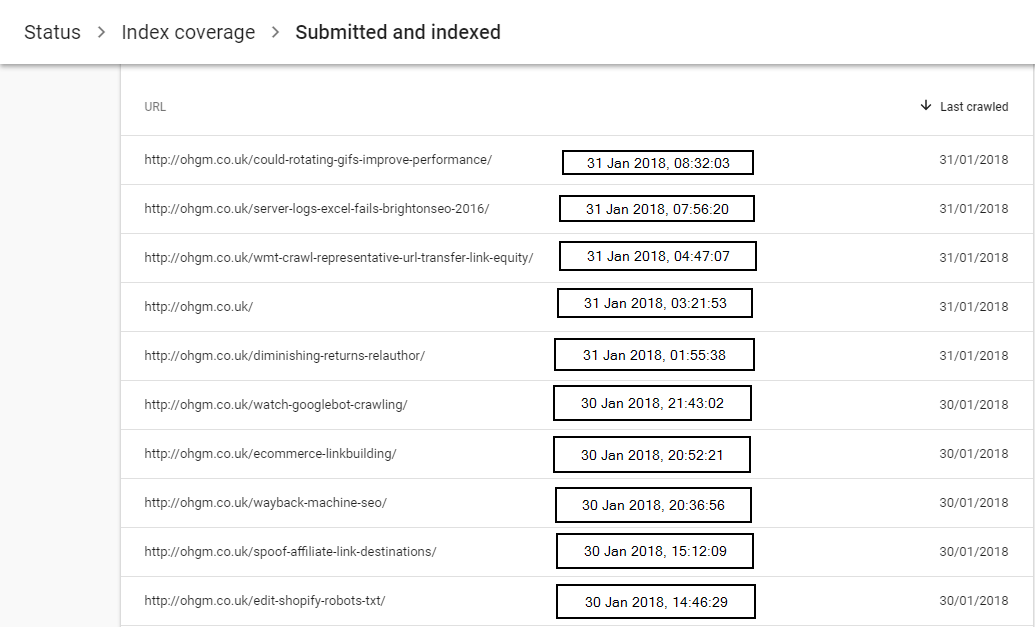
They’re all nice and unique. Now check the crawl timings on these blocked in robots.txt URLs Google is complaining about:
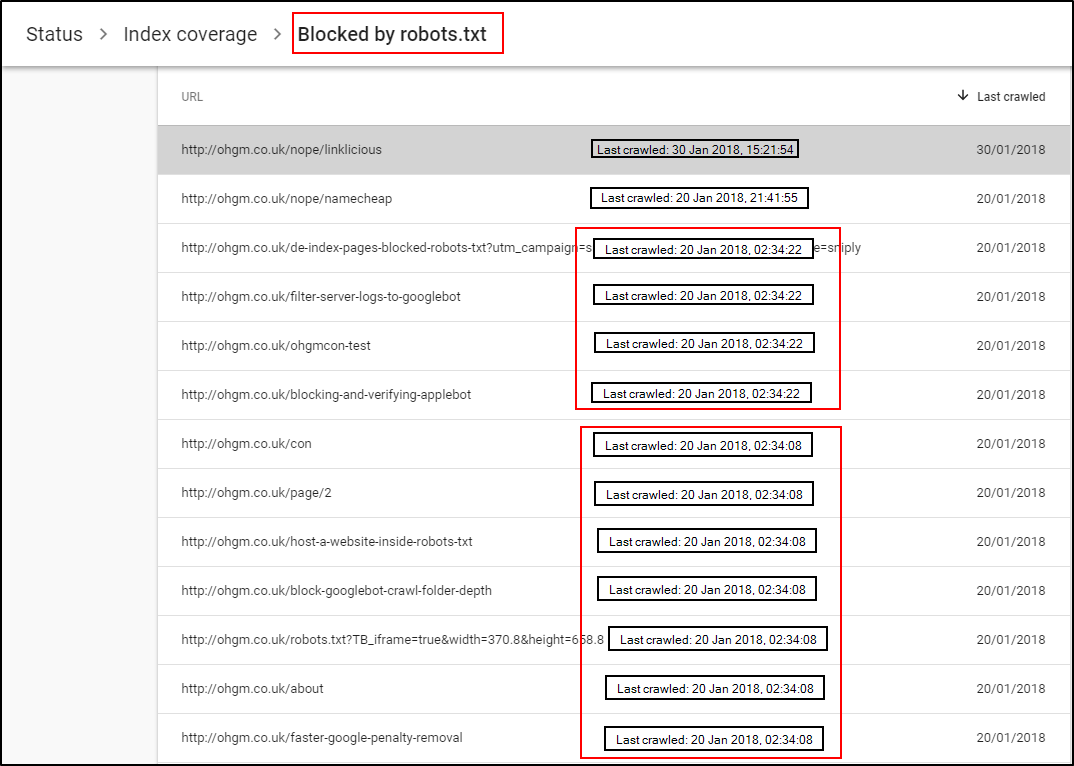
Notice the two blocks with identical timings. These ‘crawls’ were made in the same second. Obviously Googlebot isn’t crawling these URLs, because it’s very well behaved and always obeys robots.txt* (and I checked the server logs).
Attempting to crawl a URL blocked in robots.txt looks a bit like this:
- URL comes up for crawl from the scheduler.
- Before making a request Googlebot checks against the cached robots.txt . A fresh one isn’t downloaded against each request (but 24 hours is the longest they’ll use an old one).
- Googlebot finds that the URL is not open for crawling according to it’s idiosyncratic interpretation of the robots.txt file, and the URL is not requested.
- The next scheduled URL is tested.
These are very nice examples of scheduling in action. Since no requests is actually being made, just a test against a cached file, Googlebot can speed through scheduled blocked URLs. Thousands can be done in under a second if the scheduler happens to bundle them in this order.
Neat.
Bulletpoints to Aid Reading Comprehension
- Although Fetch and Render submission is Googlebot at full capabilities, it doesn’t actually count for indexing purposes. A submission may tag the URL with ‘mild interest’ for any scheduling.
- Fetch and Render with Request Indexing is a much stronger signal, but it does not force scheduling.
- A separate crawl after Fetch and Render is done for the actual indexing, and this makes sense to avoid shenanigans from people like us.
- We can trust the crawl times reported in the new search console. Those crawl times are the crawls actually used for indexing.
- The new search console reports last crawl time in local time. The old search console reported it in Google time. This is a nice feature.
- ‘Attempted Crawl’ timings for URLs blocked in robots.txt are included in last crawl timings.
* Earlier in this article I made a reference to Googlebot always being well behaved. I’d like to clarify that this was a joke. If you enjoy this sort of thing consider applying to speak at my creepy basement SEO conference.
Hi Oli,
Very interesting. A question if you’d permit me – referring to 20% of crawls being smartphone user agents – and it potentially showing you in the desktop vs. mobile first index. Do you think the reverse could be a good indicator of a switch over to the mf index? Against last crawled in SC?
Luke
Hi Luke,
I think it’s a great indicator. I’ve seen the UA swaps across a few clients in the second half of last year. It didn’t really click that we were seeing a staggered launch of mobile-first until this comment from John Mueller:
https://www.seroundtable.com/google-log-files-mobile-first-indexing-24926.html
Once I gather enough patience to run this again, I’ll test this on a site which is clearly mobile first. Then we’ll see if SC is just Desktop or Mobile crawl data, or also indicative of whether the site is ‘mobile first’.
Hi Olly,
Thanks for the response, similarly I saw a 50% increase in crawls (without any site changes) after December for a client and started digging in.
Look forward to the results of the next post.
Luke
Hi!
Great article, this makes a lot of sense in analyzing server logs + fetch and render + new GSC data. Thank you for sharing. I was wondering if you think the crawling in your local time zone could be google locale aware crawling vs your own time zone? Not sure if that lines up with your data but thought I would ask.
Thanks!
Thanks Kristan,
Locale-aware crawling is too niche even for this site – I get crawled from the USA like nearly everyone else (I have a memory that Google dialed this down because they didn’t find the data useful, but I think I may have dreamed this. If anyone can find a reference, DM me).
The crawling being reported in my local time zone is probably a result of some account configuration (I have a vague memory that you report the timezone somewhere when setting up) or localisation. It’s not too much of a leap for them to guess a .co.uk associated with the United Kingdom in Search Console would be best reported to in UK time. This is quite big conjecture on my part though, using a VPN to look from other countries didn’t change the time reported in Search Console, so it may be done on account basis, or site by site.
It’s really nice to know that the data lines up (for now).
That makes total sense, Thanks!