
This post is about how I think about Pagination.
It’s not The Ultimate Guide to Pagination (that is, by all accounts, this one), nor is it comprehensive.
Terminology
It’s frustratingly easy to use pagination terminology interchangeably, and inadvertently refer to one type of thing when you mean another. I will do this throughout the article (sorry), but in editing I will attempt to stick to the following:
Items/Item Pages– these are the URLs the pagination contains. Typically they will be product URLs (or “PDPs”), or individual articles/posts.Pages– these are the pagination URLs. The URLs which contain lists of items, e.g.?page=2or/page/2
It’s only two terms, so wish me luck.
Vanilla “Good” Pagination
I’d first like to discuss the rarely disputed best practice which I expect you will be familiar with if you are reading this. It has the following features:
- Each page is crawlable and indexable, with a unique URL, and can be encountered via
<a href=""internal links between the pages which will typically be provided in the initial HTML.
This is all that’s needed.
Under this approach SEOs will almost always ensure <link rel="canonical" is used (and it probably should be), with a self-referencing href value present on each page of the sequence. This acts as a canonicalisation hint that each page should be indexed, and not folded together.
Aim of Approach
Under this approach, the goal is for the pages to be indexed so that the hyperlinks to the linked item pages can be seen and pass PageRank.
This is all it’s trying to do, and it does it.
We Could Stop Here
If the pagination is to serve as a safety net for internal linking, this “best practice” approach is a great choice. For the majority of websites, it gets the job done. You are unlikely to get in trouble for using this method.
And it will rarely be the wrong decision.
But it might not be the optimal decision.
Because it works, it’s easy to apply without full consideration. Although I’m a big advocate of “good enough” (cue client reading this, laughing), we should at least try to know what optimal for our goals is in different scenarios, even if we aren’t necessarily going to push for it.
Despite that warning, there is a lot of latitude within the framework to optimise.
Divergence from “Good” Pagination
If you’ve worked in SEO for a little while, you’ve probably seen a couple of implementations that are not “best practice”. Most of you will be familiar with why they are bad, but I’d like to bring them to mind before we go further.
These are the villains of “canonical to root” or to “noindex page 2+”.
Canonical to Root
The most common divergence of this approach is canonical to root, whereby each Page will refer to the root of the sequence via link rel="canonical".
- If the canonical to root is obeyed, then pages 2+ will be excluded from indexing, and any link signals will be passed to the root.
- This means that pages beyond the first won’t pass PageRank to their item pages.
If you are attempting to pass PageRank via the pagination (as above), then this is an irrational approach.
However, if your goal is hoarding PageRank on the root of the sequence in order to rank better for higher value category terms at the expense of item pages, great. Or at least, it’s a start.
If that’s your goal, and you’re hyperlinking to the subpages in a way Googlebot can crawl, then this is a bit of a mixed signal. Those hyperlinks are still being assigned PageRank, but you are relying on the canonical to pass it back.
However, with canonical being more of a hint than a directive, Google can and will frequently ignore it:

And they are generally pretty good at identifying what is/is not pagination, and when canonical should/should not apply. The canonical being obeyed tends to rely on the page being sufficiently similar (see Laundering Irrelevance for a bad idea).
While we think of two pages within a pagination sequence being very similar due to their shared characteristics, the main content of most pagination is a grid of items. This is different on each page. With each page having different main content, pagination isn’t a great place to rely on Google not correcting you and accepting the canonical.
If the attempt is to maximise performance of the category page, then canonical makes more sense as the last ditch. Not the first.
Noindex Page 2+
You’ll also likely have encountered a pagination where pages beyond the first have been set to noindex.
This was in vogue for a couple of years, but has steadily fallen out of favour as SEOs eventually come to terms with “noindex is treated as noindex,nofollow over time”:

The motivation behind noindex use within pagination is usually based on a few ideas about reducing “index bloat” or “preventing the wrong page from ranking in search results”.
It’s not index bloat if it is doing something you want and it cannot do it without being indexed.
If we want PageRank to reliably pass to item pages beyond the first, we need the pagination indexed. Noindex would be irrational here.
(as an aside I think the industry obsession here is collective trauma from the Panda update being passed carelessly onto new SEOs)
If we don’t care about passing PageRank to item pages beyond the first page, then we don’t have to have a crawlable pagination.
Do things wrong; use the wrong link formats, badly implement infinite scroll/load more, cloak for Googlebot, whatever. We certainly wouldn’t need deeper pages crawled, so feel free block in robots.txt.
If you are reflexively reaching for a “but robots.txt doesn’t stop indexing”, I’d agree.
But we shouldn’t mind if URLs that aren’t linked to are being indexed without content. If they’re not showing up in SERPs for actual queries, why would we mind?
Anyway.
Visualising Pagination
My default understanding of how indexable pagination works is horizontal rather than vertical; PageRank flows along the pagination sequence, down to the item pages:

Lovely.
While this visualisation can get you quite far, it’s not accurate. I suspect this is the shorthand picture many of us hold when thinking about pagination.
Unfortunately, it’s a very unhelpful visualisation if you are attempting to optimise toward a goal.
Instead we’re really working with something more like this:

The items on the first page are very likely receiving more PageRank than even the pagination linked to from the first page (”reasonable surfer”).
Items linked to from these pages (2,3,50) will get less.
Pages not linked to from the root of the sequence (e.g. 4-49 here) are dramatically weaker, and quickly receive negligible PageRank. This trend extends to the items they link to.
This is further compounded once you consider other elements, e.g. navigation, static breadcrumb ensuring that the root of the sequence receives even more emphasis as every item page links to it.
How are we to think about this?
- If you value your item pages equally, then the above is a very bad setup.
- If you value some items pages a lot more than others, it’s a very good setup.
So far, so good.
‘Click Depth’ is a helpful concept for realigning your focus, and can be useful shorthand for thinking about this. However, the industry rule of thumb around a click depth being “three from the homepage” can be unhelpful when thinking about pagination.
It will encourage you to have broad categorisation (many subcategories), and paginations with more items and more links. These are usually very good things, but focusing on them may lead you to miss other opportunities or alternate approaches.
Pagination Levers
Here are the some non-exhaustive tweaks you can make to pagination.
Crawlability
Many sites have paginations that exist, but aren’t assigned PageRank because someone preferred the UX of infinite scroll or a ‘load more’ button and didn’t handle things appropriately.
Perhaps there’s an issue with the dynamic rendering, or the type of links used aren’t search engine friendly.
Denying routes into the pagination be very desirable if you don’t need the item pages to receive PageRank or be discoverable via the pagination (for crawlers), but wish to attempt to hoard it on the category page.
Number of Items per Page
One of the main levers to consider across any pagination is how many items you return per page.
Understandably, a pagination sequence of pages containing a single item would be actively hostile to the user, very cool, and useless. BALENCIAGA should consider it if they bring back their old website.
The following will seem obvious:
- Increasing the number of items per page will reduce the number of pages.
- Reducing the number of items per page will increase the number of pages, and maximum ‘click depth’ of the sequence.
Considering click depth in isolation is not too helpful.
The next relationship is less obvious:
- Increasing the number of items per page will increase the proportion of PageRank assigned to the items on the first page, and drastically reduce the amount assigned to items on
page 2and beyond. Each added item reduces the PageRank potentially assigned to deeper items. - Reducing the number of items per page will increase the proportion of PageRank assigned to the Pagination linked to from the first page. And although this change assigns a lot of PageRank to the products on the first page, more can potentially flow to the items on the pages linked to from the first page, than if there were more items).
- You also also have the option to return a different number of items per page, for a different outcome.
All of this will depend on the design of the pagination (we’ll consider this shortly).
I would recommend chewing on this for a while, as it’s a very slippery and counterintuitive concept.
Sort Orders
If you are able to get away from a purely chronological sort, then the most impactful lever for you to be fiddling with in most scenarios is sort order, whereby you determine exactly which items are showing up on the first pages of your sequences. Under any pagination design, these slots will be the strongest links to item pages, so it’s important to populate them with items you care about.
Many companies already use a ‘scoring’ system for how items are ranked within categories.
If you want input here, you are probably going to be speaking to the merchandising team, who will be working towards maximising profit margin or some other KPI. I wouldn’t fight them here, just feed in with what you know (e.g. “What’s the margin on X? We currently rank quite poorly but would expect to double organics sessions by getting on the 1st page)”.
There’s a very human tendency to prioritise by existing performance (e.g. the products that have historically contributed the most revenue).
The trick is to not delight when items that score poorly under this model proceed to perform poorly, for the model will be the cause of their weaker internal linking (and poor performance).
Which Pages are Linked to
Imagine a 5,000 item “best practice” pagination, with 50 indexable pages of 100 items each.
Keep those numbers fixed.
Now, imagine you are on /page/15.
What exactly does the pagination look like?
There isn’t an answer.
14 15 16
Next/Prev (Neighbours)
1 … 14 15 16 … 50
First, Last, Neighbours
1 … 13 14 15 16 17 … 50
First, Last, Two Neighbours
1 … 6 … 14 15 16 … 33 … 50
First, Last, Midpoints, Neighbours
Again, I would really strongly recommend reading Audisto’s guide here, as I wouldn’t be able to improve upon this. Then, ask yourself:
- Under each design, how many clicks from the start of the sequence is page 15?
- In a 50 page pagination, how many clicks would it take a determined user (a crawler) to reach any given page?
- Which is the absolute weakest page on this model?
- Does it matter?
What I’d like to get across is that all of these decisions have consequences for PageRank flow, and the person who designed your pagination probably (rightfully) wasn’t thinking about them.
Last Thing
If we take a “lower click depth” approach, then a templated link to the Final page halves your ‘ceiling’ for depth. Great!
But it also makes page 50 stronger than page 2. Every page links to it.
If you have an intelligent sort order, this is a very bad idea. In the example scenario there are 4,950 other items you care about more than these.
First Thing
Similarly, you could consider abandoning the “all pages link back to the start” trope (if you wish to make the spread a little more equitable).
This isn’t too radical – “Next page, previous page” is a very common pagination structure once you start noticing it.
I’d liken this to trying to put out an oil fire by spitting on it, but every little helps.
And The Answer is None, None More Flat
If you are pursuing a more equitable spread across all items, then you’ll be served well by aiming for a lower maximum click depth, and avoiding obvious nodes (e.g. first, last, fixed point).
And if you start thinking about this, you’ll soon realise that the flattest pagination possible is a “view-all” page (which is to say, no pagination at all).
This is, I think, what Google may have been inadvertently hinting at with their gentle celebration of ?view-all pages in the past.
Under such an approach you canonical each page to a view-all, and Google uses this for indexing.
Serving a view-all page has plenty of drawbacks e.g:
- It will be incredibly slow on most platforms once you’re above 100 products.
- UX will fight you.
- Landing on a
/?view-allsucks.
I don’t think Google deciding to serve a referenced view-all page in Search Results has ever been popular. But we can avoid that crime scene by serving this page only to bots on the same URL.
This still has disadvantages, but they’re limited to bots. A slow and onerous view-all page (for Googlebot only) may be less onerous for Googlebot than processing a regular pagination.
Another benefit of doing away with pagination (for search engines) is that it does not give them a choice. Either they crawl it and index or they don’t. They don’t have the option of deprioritising crawl of deeper pages, because there is only one page.
Aside: What I think the appropriate thing for Google to do would have been to make it clear that cloaking is acceptable in this context, provided the only difference between the core content of the pages is that one returns X items on a single page, and the other returns X items over N pages.
I have begrudgingly recommended this as a cloaked alternative to pagination (uh, dynamic rendering) for a surprise migration before. It is still in place years later without apparent issue. Your mileage may vary.
What’s Available / Limits
This is a pseudo consideration, but another way to ensure some items receive more PageRank than others is to exclude the others entirely.
The first (and I think universal recommended) stage of this approach is to evict items from the pagination – e.g. sold out products. Very normal SEO, and something we do on occasion without realising. For example, you have probably advised against linking directly to product variants from PLPs before.
But there’s a variant on this approach I’d like to explore.
Perhaps of the 5000 user-facing items you now feature, fewer than 150 are of genuine potential value to the organic channel (see again: scoring systems).
You don’t actually have to allow crawl/exposure to item links beyond this 150.
This is a potential acceptable compromise position for massive websites – you can have a crawlable, search friendly pagination, up to a point.
We tend to think of crawl restrictions in absolutist on/off terms, but should recognise this is self imposed. There is a lot more granularity possible here than we are in the habit of accepting.
So, when it no longer suits you, restrict access or exposure (hide links) for crawlers. Users can still persist as normal. If you are using a scoring system, you can make this behaviour dynamic.
You don’t owe Googlebot access to all the URLs on your website, and saving them the journey can be mutually beneficial.
This sounds like quite aggressive SEO, and perhaps it is, but it may come in useful in future.
Alternate / Secondary Sorts
Best practice pagination will block crawl of alternate sorts (e.g. Price High-low, oldest-new) using robots.txt, and better yet, not generate crawlable links to it. This is the correct approach, and Google seems to prefer you do this:
Avoid indexing URLs with filters or alternative sort orders. You may choose to support filters or different sort orders for long lists of results on your site. For example, you may support ?order=price on URLs to return the same list of results ordered by price. To avoid indexing variations of the same list of results, block unwanted URLs from being indexed with the noindex robots meta tag or discourage crawling of particular URL patterns with a robots.txt file.
https://developers.google.com/search/docs/specialty/ecommerce/pagination-and-incremental-page-loading#avoid-indexing-variationsAlternate sorts don’t expose them to anything new, wasting their time. It’s understandable they would be against them.
However, consider the scenario of a large website (>1m item URLs), with well optimised custom sort orders. Now imagine it’s one that with a frequent influx of new content.
Under most scoring systems, this new content is untested. It has indeterminate expected value.
Even if we attempt to compensate, the scoring system will tend optimise for what does well already, and some new content may appear on page 2+ as a result. It might then be buried deeper as yet more untested item pages arrive. How it performs may well depend on the luck of the draw – how frequently Googlebot decides to recrawl the URL vs how frequently items are added.
So instead of getting a scoring system to do two different things, we can create a proving ground to feed into that system. A second pagination, containing only the absolute newest items within a category. This is really no different than a subcategory, though I would suggest combining this with the Limit concept explored above e.g. 50 most recent items, 1 in 1 out.
I touched on a variant of this concept in An Alternative Approach to XML Sitemaps.
This gives the pages a chance of getting sufficient PageRank before they are buried, and the ability to fight for a place in the actual sort order.
A “New In” link can slot right alongside a “First” link in a pagination sequence to get links from each page, ensuring it has PageRank to pass.
Usually Improvements
Pagination Index Status
When it works, pagination acts as a safety net mechanism for internal linking.
When it works.
If a page isn’t indexed, then it won’t be passing PageRank. And if it’s not passing PageRank, then what is it doing for your item pages?
So if you think your pagination is important, you should find out the state of play.
The quickest way to see the current state of play is by using the URL inspection API using Screaming Frog (or another crawler) against a list of pagination pages (not items). The results can be upsetting:

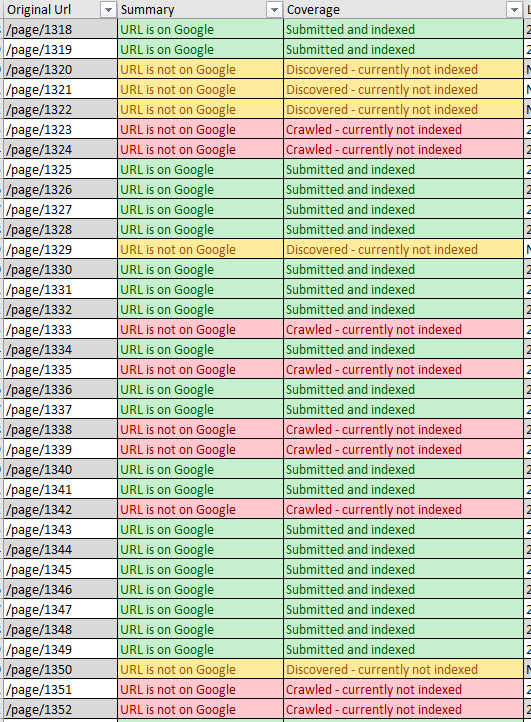


This is a sequential pagination, and you can see an uncomfortable trend.
You will see the proportion of URLs they haven’t bothered to crawl, and the proportion they’ve yet to index. In either instance, the linked item pages aren’t going to be getting PageRank (and for “Discovered – currently not indexed”, the benefit of discovery) via this channel. All will likely underperform as a result.
What I recommend to not be surprised by this discovery if you have large paginations (and value the item pages) is a dynamic XML Sitemap of your pagination.
I know some SEOs must do this, but I’ve not seen it as advice in a blog post before (though I have seen the opposite).
Including a separate XML Sitemap for pagination does three things:
- Allows you to track the rate of indexing easily in Google Search Console, allowing you to see the impact of changes to your pagination on indexing.
- Increases crawl priority to the URLs contained within.
- Acts as a further hint for canonicalisation (much like self
canonicalreferences), emphasising the independence of these pages, and signalling that yes, you do consider them to be distinct and want them indexed.
To make that position explicit (so you may reject it):
I believe the mere presence of a URL in a submitted XML Sitemap increases the likelihood that it will be indexed.
I agree that usually including pagination in XML Sitemaps will carry close to zero benefit, but if you need to know, it will really be worth doing.
If you want to minimise emphasis on the linked item pages, and aren’t treating the pagination as an internal linking safety net, then I would advise against using an XML Sitemap here.
Templated Uniqueness
If you want pagination indexed, make it obvious that they are distinct page so that Google will be disinclined from folding them together.
For example, using the self canonical mentioned earlier. Here I’m recommending unique title elements. Google of course say this isn’t absolutely necessary:
Normally, we recommend that you give web pages distinct titles to help differentiate them. However, pages in a paginated sequence don't need to follow this recommendation. You can use the same titles and descriptions for all pages in the sequence. Google tries to recognize pages in a sequence and index them accordingly. -https://developers.google.com/search/docs/specialty/ecommerce/pagination-and-incremental-page-loading#sequentially
Given the lack of downside, I’d still consider doing this if you’re making other changes to the pagination. The potential impact is an increase in the # of indexed (pagination) pages.
Page 1 Duplicates
Most custom paginations will, by default, accidentally generate access to a duplicate page=1 or /page/1.
This will be linked to from the previous button on page 2 (which isn’t a massive issue), or from links to 1 or First in the pagination element (which could be).
Sometimes this will correctly canonical to the root of the sequence.
You already know how to fix it.
Helpful Pagination Questions
- Do you care about the performance of individual item pages as organic landing pages?
- If so, then you’re going to want an indexable pagination.
- If not (and really, make sure), you may be best served by making the pagination hostile to crawlers.
- Does your pagination include anything that shouldn’t be there?
- If you care about item pages, do the item pages you have possess roughly equal expected value for the business?
- If so, then you may want to consider reducing the depth of the pagination, increasing the quantity of paginations you have (more subcategories), or abandoning pagination for crawlers (view-all).
- If not, then you are going to want to investigate priority:
- Sort orders, expected values, alternate sorts.
- Whether to expose the entire pagination, or just part of it.
- How many items are revealed on each page.
The End
PageRank being iterative makes it incredibly unintuitive. I will never actually understand it, but am happy enough approximating it in crawling tools. Is this level of granular thinking pointless? Frequently.
Thanks for reading and I hope this gave you some ideas.
Post written in lieu of ohgmcon, thanks to everyone who messaged about it, I promise I wasn't just letting you down gently. ( ͡~ ͜ʖ ͡° )
> Pages – these are the pagination URLs. The URLs which contain lists of items, e.g. ?page=2 or /page/2
I always refer to these as “listing pages,” and in fact in your article, you also describe them (once) as PLPs.
Why not use the somewhat standardized terminology of two page types, product pages (PDPs) and listing pages (PLPs)?
There are two things I hate about technical SEO. Two issues I never really could wrap my head around. Those are pagination, and faceted navigation. Somehow, you almost end up mixing the two…
This is a great read. Can you give a visual example for pagination on a blog section with 5000 item pages.
i understand the need to add self-referencing canonicals on each pagination page if you want it indexed.
the issue i have is with designing a pagination to reduce crawl depth. Like making sure every pagination page is at maximum 4 clicks away from the home page or any other pagination page.
can you provide some visual examples of that?
thanks
>> If we take a “lower click depth” approach, then a templated link to the Final page halves your ‘ceiling’ for depth. Great! But it also makes page 50 stronger than page 2. Every page links to it.
This made me think: In case the products are sorted logically by their value for the business, what about setting the “last” link as nofollow? Only in cases when page 50 becomes a “neighbour”, the link will be set to follow. We keep a good UX and the first pages will retain the highest Pagerank. Does it make sense?
Hi Daniel,
Page 50 would no longer be the 2nd most important page, but as I understand it, the more valuable pages in the sequence wouldn’t get any additional PageRank by this link being nofollowed (the PR gets assigned and discarded on each page that links to it). It’s a tricky topic and it really depends on what you’re trying to achieve, and whether it’s worth it. This older post has some thoughts on it – https://ohgm.co.uk/its-not-all-about-pagerank/