
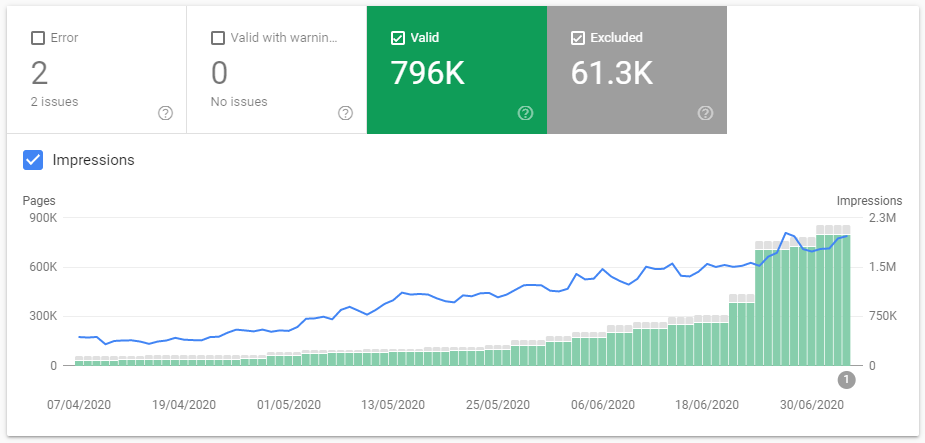
Here’s a screenshot I took of a website’s submitted URLs last year:

And here’s that same report around 6 months later:
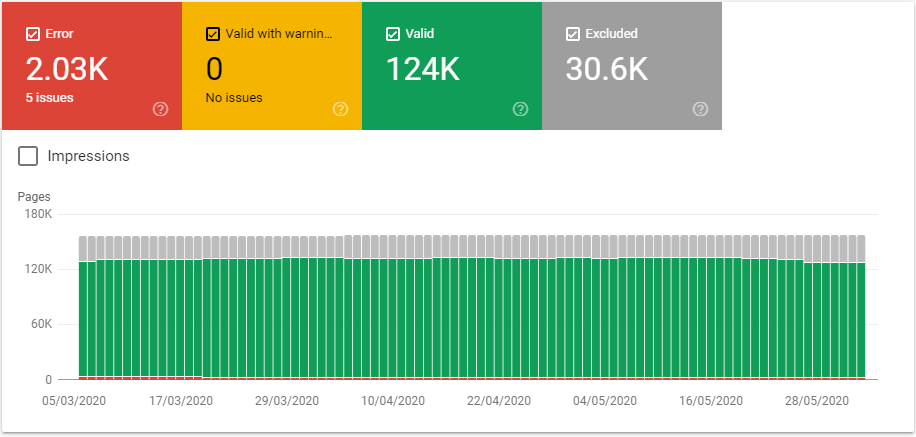
The number of submitted URLs has fallen from 159k to 156.6k, but the number of indexed URLs has increased from 105k to 124k. Nineteen thousand more URLs are now eligible to receive organic traffic. One template went from 58% of URLs indexed to 76%.
I realise this isn’t a hockeystick graph, but I still think it’s worth sharing. There are some brain-feel-good graphs later, this is just to ease you in.
This is an ecommerce site with a substantial inventory, but there is no faceted navigation to contend with – only category pages, pagination, and product pages. The content quality did not improve. No active linkbuilding was undertaken. The internal linking to these pages which became indexed did not improve substantially.
What Changed?
I think everyone agrees in splitting XML Sitemaps by page type to make auditing and understanding what content is being indexed easier. This website was already doing this. But they were also doing this:
"All formats limit a single sitemap to 50MB (uncompressed) and 50,000 URLs." (Source)
This number is often included in the copy-paste recommendations of heavily templated audits, which is why we see it so often on new client websites. Thanks!
Instead:
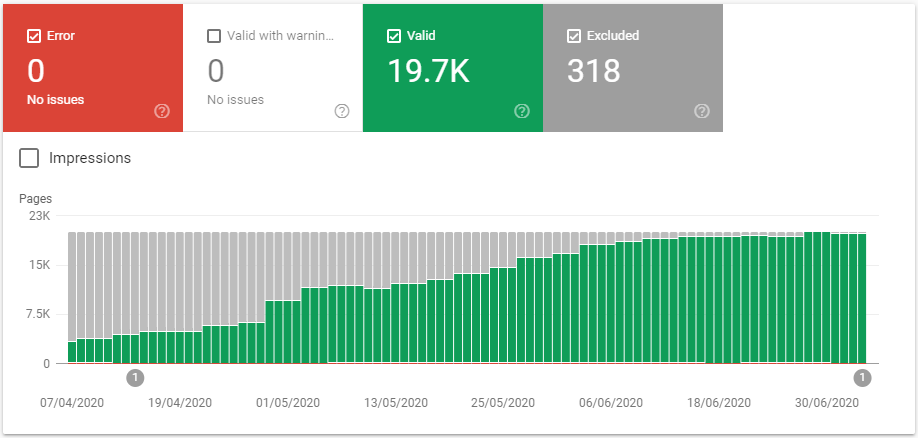
We moved from a few XML Sitemaps capped at 50,000 URLs to many XML Sitemaps containing 10,000 URLs. This took us from ~5 XML Sitemap files to ~15.
These smaller XML Sitemaps are organised chronologically, with products1.xml containing the oldest products, and products14.xml containing the most recent products. The indexing behaviour goes how you might expect:

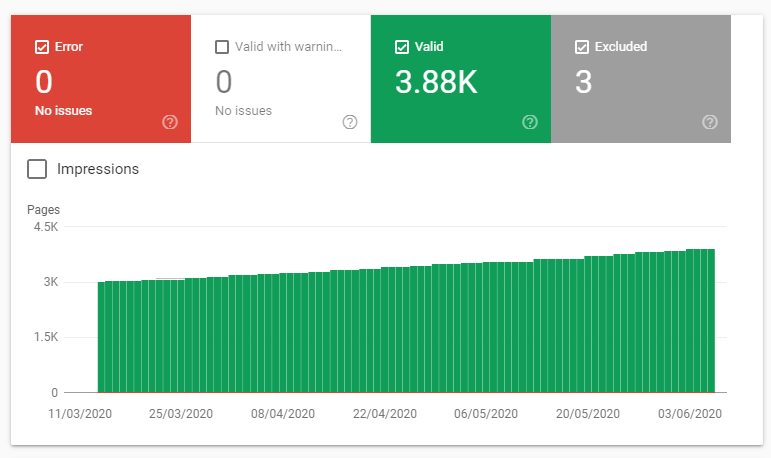
This makes sense – older products are more likely to be buried deeper in the internal linking architecture, and as a result receive less internal PageRank.
Whilst this is true, I don’t think it’s the correct explanation here. This particular website is heavy on discontinued products. This makes the older pages more likely to be “lower quality” and far more likely to be identified as soft 404s, whilst the new products being added are in stock.
You probably notice that this is gradually tailing off, which is not unexpected considering none of this content has improved, and these products aren’t being restocked.
I’ve been intrigued with the idea that the amount of short-term storage available impacts the indexing of lower quality content (thanks to Martino for finding the tweet). I’m especially intrigued as you could use this idea to identify areas of the website which could be classified as ‘nice to have’ (i.e shit), from Google’s perspective by the ‘will-they-won’t-they’ indexing behaviour. I also like to think they have multiple copies of the index by date on tape archives in a disused missile silo somewhere.
How Does This Work?
I haven’t seen this idea written about a lot, but it is talked about by SEOs. I managed to find Barry Adams had previously written about this approach, and shared his thoughts and observations:
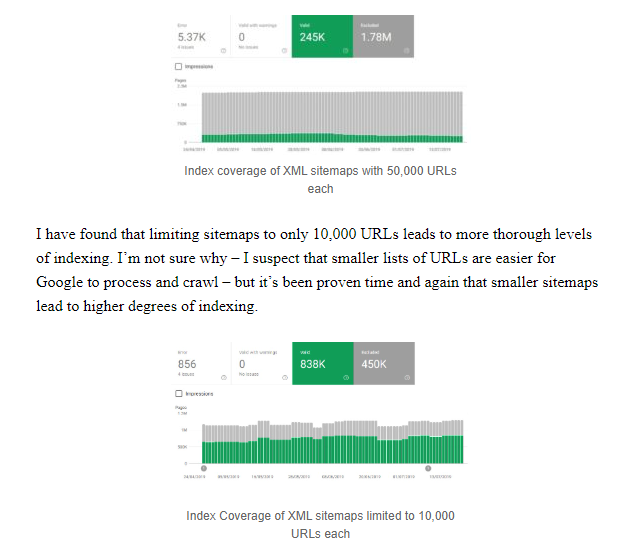
"I have found that limiting sitemaps to only 10,000 URLs leads to more thorough levels of indexing. I’m not sure why – I suspect that smaller lists of URLs are easier for Google to process and crawl – but it’s been proven time and again that smaller sitemaps lead to higher degrees of indexing."
(I wasn’t sure these were the same sites as there were 2,025,000 vs 1,288,000 URLs submitted – I checked with Barry and he confirmed they were different websites).
I understand some SEOs push for 1,000 URL Sitemaps so they can get around Search Console limits so it can be used to monitor which URLs aren’t getting indexed. I believe they are also accidentally being very efficient in terms of indexing.
I don’t actually know how this works, just that every time I try it, more pages end up indexed. It may be a coincidence.
This isn’t an ideal consulting position, so I’ve spent more time than is reasonable thinking about XML Sitemaps and put some thoughts together in case a client asks something awkward like “How does this work? {Google|Moz} says this is fine“. Here are some suggestions:
- Sitemaps with fewer entries are significantly easier to process. They also tend to be faster to download.
- Lighter Sitemaps (in terms of filesize) are faster to download and are easier to process. This is similar, but different.
- Frequently updated sitemaps get crawled frequently. You might experiment with rotating sort order in order to simulate this. Redoing your sitemaps like this forces a dose of ‘novelty’
- Related: Google does not wait around for your server to cough and splutter through the transfer of the larger file, and it doesn’t relish expending the resources parsing 50,000 lines either.
"Each Sitemap file that you provide must have no more than 50,000 URLs and must be no larger than 50MB (52,428,800 bytes). If you would like, you may compress your Sitemap files using gzip to reduce your bandwidth requirement; however the sitemap file once uncompressed must be no larger than 50MB"(source)
I’m still not getting anywhere, but thinking about XML Sitemaps has gotten me somewhere more interesting.
Google News Sitemaps
Consider the Google News XML Sitemap format. If you’ve done log analysis for sites in Google News, you’ll know those things get crawled. Lots.
Why is this the case? If we review the guidelines:
"Include URLs for articles published in the last 2 days. You can remove articles after 2 days from the News sitemap, but they remain in the index for the regular 30-day period."
"Update your News sitemap with new articles as they're published. Google News crawls News sitemaps as often as it crawls the rest of your site."
Compared to normal XML Sitemaps, News XML Sitemaps change frequently and contain fresh novel content. For many larger publications, each time Googlebot requests the XML Sitemap, it will be different. I think the novelty is doing a lot of the work in determining this.
"Add up to 1,000 full URLs to include more, break these URLs into multiple sitemaps, and use a sitemap index file to manage them. Use the XML format provided in the sitemap protocol. Do not list more than 50,000 sitemaps in your sitemap file. These limits help ensure that your web server isn't using large files."
We are even further discouraged from using large files, which makes me think smaller files are better.
"Update your current sitemap with your new article URLs. Do not create a new sitemap with each update."
We are encouraged to keep the URL of this “gateway” sitemap static, whilst the contents change.
These are probably totally different systems and it might be that it’s not really regular Googlebot crawling it when it’s hammering those requests. It doesn’t matter, we can still apply the theory to how we treat regular sitemaps.
My general recommendations are around making XML Sitemaps with fewer URLs, when perhaps they should be about making smaller XML Sitemaps (as in file size). I don’t really believe this but I am now ruining my own website by adding cruft to the start of the post Sitemap, so it weighs in at a hefty 48.6MB. Enjoy, Googlebot:

I’ll update the post when {something|nothing} happens. I can’t try this out on a real website, unfortunately.
An Alternative Approach to XML Sitemaps
I understand that so far, this wasn’t as weird as posts on this blog tend to be. I’d like to share something with actual value.
This approach is useful if it is valuable for your content to be indexed ASAP, and if your content has a decent chance of being indexed on its own merit. It is also valuable if you have a lot of URLs not currently indexed that need indexing. Admittedly, these are both rare needs, but I was lucky enough to work on a project that required both with, crucially, a client willing to implement them.
Here’s the whole idea:
You can dynamically populate your XML Sitemaps based on what Googlebot is crawling.
Here is a brief sketch in terms simple enough for me to understand:
- You have a list of URLs you want Googlebot to crawl.
- You generate an XML sitemap based on a restricted slice of the most recent of these URLs (in this example, the top 20,000).
- You monitor your access logs for Googlebot requests.
- Whenever Googlebot makes a request to one of the URLs you are monitoring, the URL is removed from your list. This removes it from /uncrawled.xml
- This is appended to the appropriate long-term XML Sitemap (e.g. /posts-sitemap-45.xml). This step is optional.
To be extremely clear – please have a professional developer write this rather than an SEO.
The benefit? New, high priority content gets indexed as soon as possible without resorting to other ideas. Once you have this set up it does not take long for it to start working:
The second image takes a while to understand. Far more than 20,000 URLs appear in the XML Sitemap per day, but the size of the sitemap is capped at 20,000 entries. The number of URLs Search Console is reporting on here only represents the sitemap at one particular time, with the rate of indexing of this snapshot of URLs rapidly increasing. This is getting far more than 20,000 URLs per day crawled.
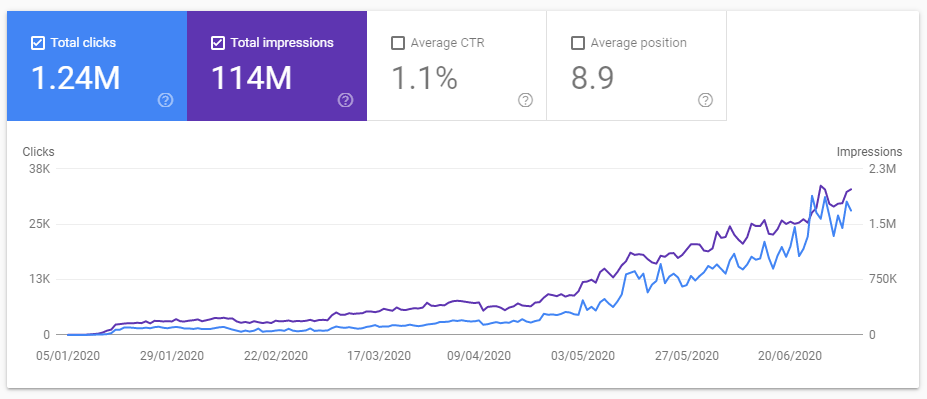
Of course I can’t attribute the success of this project wholly to XML Sitemaps…
An Alternative Approach to Internal Linking
You’ve guessed it. Here’s a second idea, built off the same approach as the first:
You can dynamically control your internal linking in response to the URLs Googlebot is crawling.
That’s it.
This uses the same methodology as the XML Sitemap generation, but to populate a severely size limited internal linking widget.
Googlebot cannot visit a single URL on this website without being exposed to novel URLs it has not crawled yet, like an incredibly aggressive re-targeting campaign. It is almost cruel.
Even though these link widgets are site-wide, Googlebot will only see the link on a few URLs at most with this approach before the links are updated. The site above has a lower DR than ohgm.co.uk, so it is not just PageRank doing the work here. You cannot calculate internal PageRank from this sort of internal linking based on a first crawl of the website.
You also don’t have to show these links to users if you don’t want to, but the position of the internal links is probably what determines the success of this approach.
Just to emphasise, this all relies on you having your other basic SEO correct. You need ways for this content to receive PageRank and anchor text and all other “good” signals once it’s beyond the very temporary limelight.
Thanks for reading!
If you’ve read this far, share the damn post.
I really enjoy the way you think about SEO.
Every time I get notified by RSS that you publish something, I drop all other bookmarks instantly ;)
This the tweet you referring to from Gary about low quality index? https://twitter.com/methode/status/1219912072399597568
I tried the internal linking concept couple of years ago on a leading realestate portal in Australia and worked wonders ( as part of controlled test).
A possible explanation:
The number of crawlers assigned to a website increases with website size, since time is a finite resource.
One crawler can handle one sitemap at a time, which means a large sitemap will not be handled in full within the allotted time.
More smaller sitemaps can be handled by several crawlers working in parallel.
@Milos a test maybe? Several simultaneous crawlers will surely leave a footprint in the log files. I’ll look into that.
I Will try this method for my website. Thank you for this post
So, after reading and re-reading, how are we meant to limit the XML sitemap, Just get a dev to do some coding wizardry?
Generally this will be configurable from whatever the website is using to generate XML Sitemaps.
For example, with Yoast: https://yoast.com/help/xml-sitemaps-in-the-wordpress-seo-plugin/#limit
Or RankMath: https://rankmath.com/kb/configure-sitemaps/
(these are both bad examples as they default sizes are 1000 & 200)
If your Sitemap solution was custom built it may be faster to involve a developer.
This is the Twit by Gary Illyes you were looking for: https://twitter.com/methode/status/1261259179983081473
(I also struggled A LOT to retrieve it, apparently it doesn’t get retrieved with basic queries… you’ll need search operators, as it was discovered on the major italian SEO bullettin board: https://connect.gt/topic/241859/rant-google-non-funziona-pi%C3%B9 but I digress)
Thank you Martino, that’s the one I was looking for! – I’ll update the post.
> I’ll update the post.
I’m actually curious to see what happens to that very Twit in Google search after that.
As I said on Twitter… I tried Googling it cause I didn’t remember the exact source.
Albeit I did a series of pretty specific queries, Google aswered only with generic c**p and I got really frustrated.
For queries like [google deindex stuff to free space] a forum pops up WHILE THE VERY TWIT DOES NOT.
Theory is: that Twit is buried deep in some secondary tier index that gets queried only when search operators are used.
Hypotesis: when the twit gains some more pagerank, may be moved in the primary index.
Test: if the hypotesys holds true, the twit should be recovered with queries the like of [google deindex stuff to free space]
Let’s see how it plays out!
Never mind, the twit pops up right now with that query… experiment: broken!
Ho yeah nice stuff here that you show us! Thanks
Never thought of doing this, I try to have some best info on my website regarding what I just read
Thanks Arthur!
Thanks for this approach.
How do you treat the dynamically generated sitemaps when google at some point indexed all pages and there aren’t any further pages on the “uncrawled” list.
How do you ensure that all those pages stay in the index? Do you use some mechanism that e.g. checks for pages that haven’t been visited by Google in the last month and that adds them to the uncrawled list again?
Do you already have experiences with the long term success of this method?
I am also interested if you linked the 10k Sitemaps of your first approach in your sitemap-index file or if you think that, for a test, it is enough if you just submit the URLs to the 10k sitemaps via Search Console?
Thanks
Hi Mike,
1. They would become empty, but this hasn’t proved an issue for this particular site just yet.
2. Can’t guarantee they remain in the index, but ensuring there is good internal linking in place is the key method here. I also raised the idea of “storage” XML sitemaps which are much more static, though I think this is a much smaller “remain indexed please” signal than content quality or internal linking.
Re-inclusion isn’t a bad idea – my understanding is that once Google has been exposed to a URL, it knows about it, so the re inclusion in this XML sitemap may only raise the crawl priority assigned to this particular URL (if it’s not already in a storage XML sitemap). If it dropped out of the index, there was probably an issue with the content quality or the internal linking.
3. Can’t say ‘long term’ really, but the site used in this article now has over a million pages indexed. I suspect the limiting factor here is probably External PageRank (the website doesn’t have much, so the rate of indexing should reduce with the size of the website as it increases).
4. So the examples are two different websites here, but I think it would be enough to just submit the XML sitemaps in search consoles (there’s probably some ‘not showing competitors’ advantage here, too).
Thanks for the comment!
Thank you so much for your quick response!
I am testing this out for my own site now (around ~100k URLs in total but only around 60% indexed right now) I split the 2 50k sitemaps into 10 10k sitemaps and submitted them via GSC while the sitemap-index with all other sitemaps remains the way it is.
I’ll try to contribute my experiences in a few months, when I can see the results :-)
Best regards from Germany
Awesome read!
For the dynamic internal linking, do you have any information about how it was developed and how much effort it took?
I assume it applies cross-links between categories and cross-links between product detail pages?
Many thanks in advance!
When your content really sucks even that won’t help, I have +500 sitemaps on one domain with some of them as small as 2k and even on those +35% is unindexed
Thanks for this post!
Does it make sense to go with “dedicated” image sitemaps?
i.e. strip them out of the regular sitemaps.
e.g. in a product sitemap to not include the associated product image.
I want to confirm whether I have correctly understood the alternative approach. For example, our website has 500K URLs, and we update 20K URLs daily through a single sitemap. This way, the URLs get indexed and ranked faster. Did I understand it correctly? I would appreciate your help.
Hey – the approach is that the content of the XML Sitemap changes based on the URLs Googlebot is actually requesting.
Once Google requests a URL, it is removed from this smaller XML Sitemap.
Think of it as a regular dynamic XML Sitemap, but instead of changing based on when posts are added/removed on the site, it changes based on when Googlebot has seen them.