
The results of my recent post ( breaking the head quietly) bothered me, since they didn’t sit right with my picture of how things work.
Rendering is supposed to behave a little like a browser. And Indexing is supposed to currently be based on the rendering engine of Chrome 41. But search engines have to make decisions browser vendors do not, and these lead to unforeseen quirks and distinctions. Some of the things a browser will ignore, a search engine will need. And knowing where these quirks might cause problems is probably part of your job.
Here’s the source used for the test:
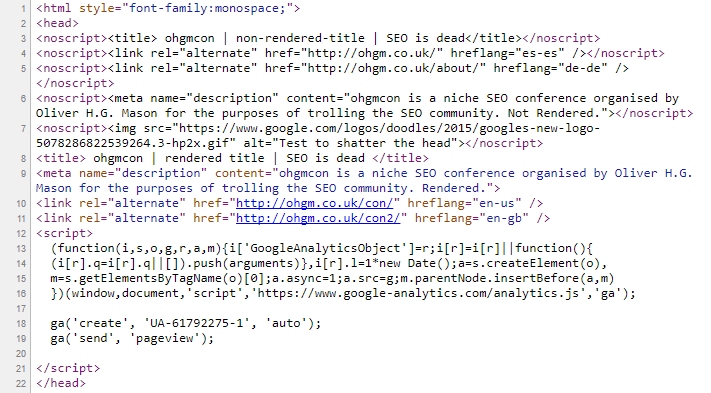
You can see this here. Here are the features of the test as I see them:
- The head has a title, meta description, two hreflang directives and an <img> wrapped in noscript tags. These have unique identifiers.
- The head then has a title, meta description , and two hreflang tags. These also have unique identifiers.
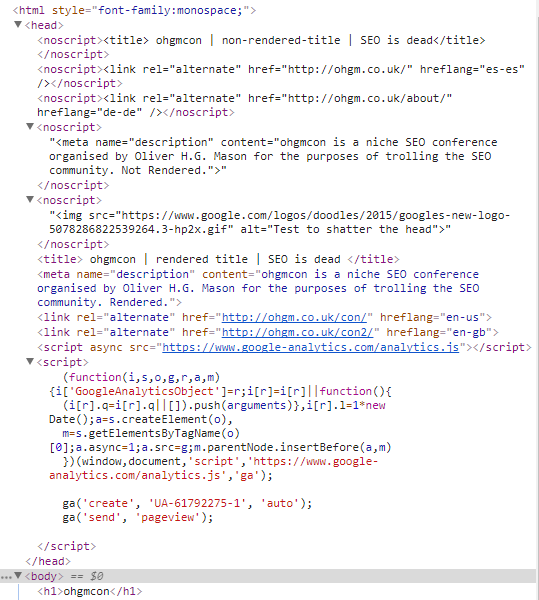
Here’s what this looks like in developer tools with JavaScript enabled:
And JavaScript disabled:
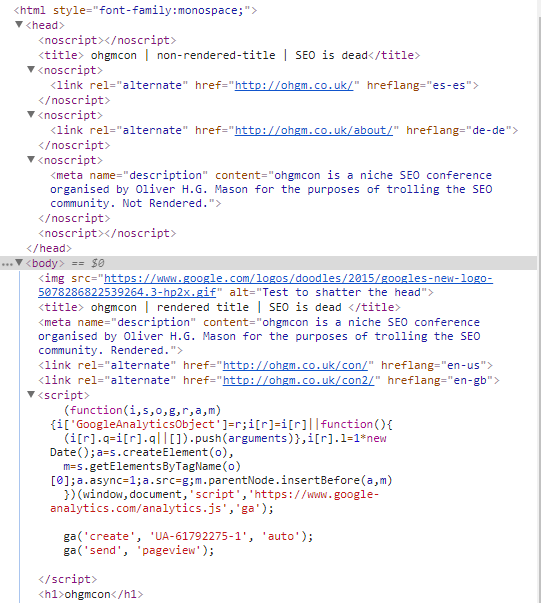
With JavaScript disabled the browser terminates the head early, forcing some directives into the body. How do you think Google will index this content? Which title and meta-description will appear in the SERPS?
https://twitter.com/ohgm/status/941686186258681856
Make a prediction.
~
What will happen?
~
Why will it happen?
~
Are you confident?
Initial Results – Titles and Metas
Once the update was indexed, Google seemed to favour the title in the <noscript> tags, before the potentially head terminating <img>:
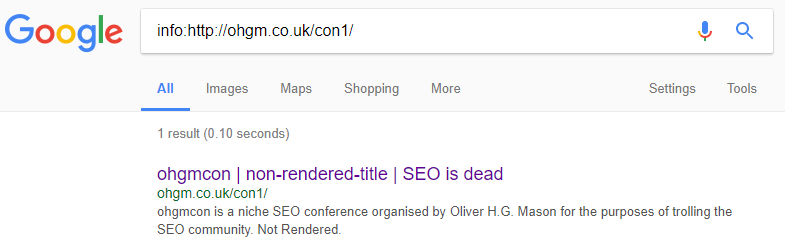
This has held for over a month and I’ve not seen any substitutions happen. Is this the outcome you predicted?
You may be thinking “So what? They just picked the first title tag and meta”.
If they did, it’s interesting, because this isn’t how your browser (or Chrome 41) behaves:

Your browser interprets and translates tag content wrapped in noscript tags into text (‘<‘ + ‘>‘), and ignores it accordingly:
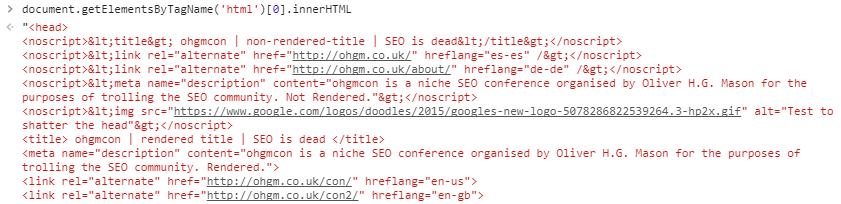
This is why your browser shows ‘rendered title’ when you visit the page. The tags wrapped in noscript aren’t interpreted as tags. If you want to try it out in your developer console:
document.getElementsByTagName('html')[0].innerHTMLWith JavaScript disabled we can see this substitution does not take place, so the tags are interpreted by the browser:
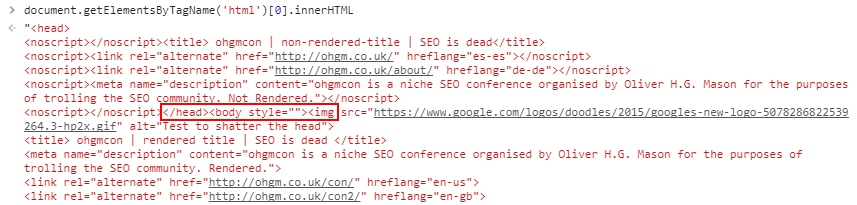
Incidentally this causes the head breaking issue.

Google is not making this substitution when it indexes, so these tags within noscript are being interpreted as tags. A few things could be happening:
- Only one tag can be used. Google sees both tags but simply takes the first in the HTML. It’s brutal raw extraction.
- The head terminates early (Google is not escaping the IMG either), so Google only sees one title and meta. Hence these are the ones which are used.
- Title and Meta Description get special/not-special treatment because they can’t really be used to cause significant harm. JS is enabled so the IMG does get escaped and the head is not broken, but the noscript-wrapped-tags that belong in the head (<title>, <meta>) do not get escaped and are evaluated as normal.
Hreflang on ohgm.co.uk
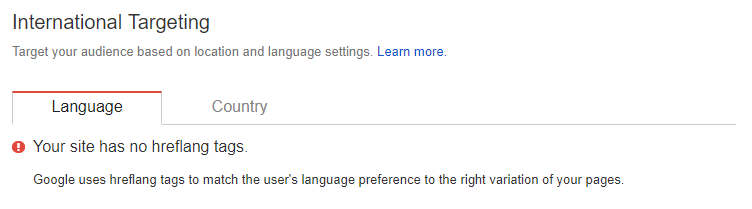
ohgm.co.uk did not have any hreflang tags until this test:
If you recall, the test code contains four potential hreflang tags for Google to pick up:
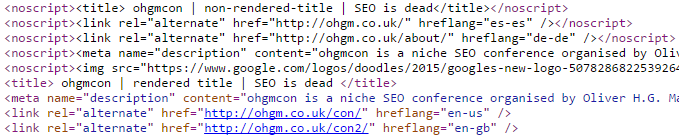
The first two are wrapped in noscript, like the title and meta. The possible outcomes of this test would seem to be:
- Google indexes no hreflang tags.
- Google indexes all four hreflang tags.
- Google indexes only the <noscript> hreflang tags.
- Google indexes only the clean hreflang tags after the <img>.
Other outcomes are of course possible, but one of the above seems most likely.
Given what you now know about which title is appearing in the SERPS, what do you predict will happen and why?
Make a prediction.
~
A brief aside – I was impatient for this report to be updated. The page had been indexed with the new content on the day I made the test, but nothing appeared in the hreflang report for several days. I did some digging across profiles and saw this pecularity I’d never thought about before.
The hreflang report in Google Search Console alternates between updating every 3 and 4 days like so:
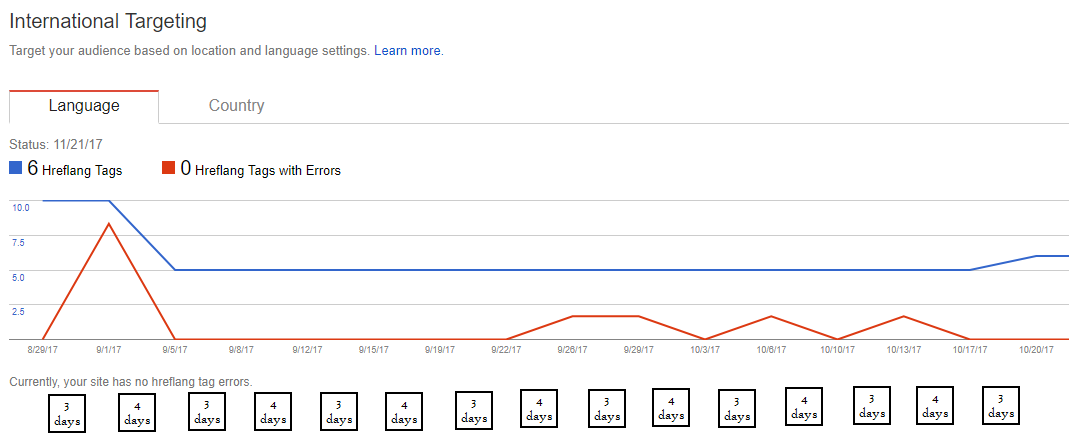
This is weird, but go and look. I did not know this before, and I hope you didn’t either otherwise I’ve just wasted 20 seconds of your time. Sitebulb user Tom Blackshire guesses that this is because the results update twice a week, and 3.5 days does not gel with daily refreshes, so 1 week = 3+4 days. The report defaults to 28 days so this kind of makes sense.
Hreflang Results
We had results in the 1st 3-4 day refresh after the changes were made to the page.
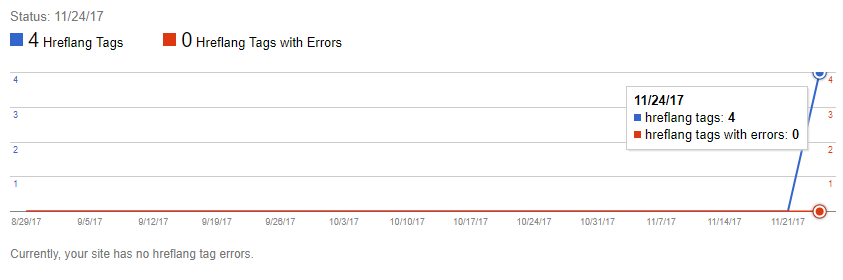
All four hreflang tags were identified, so noscript isn’t being honoured like a browser would. To me this indicates that one of the following is true:
- Google is just extracting from the raw downloaded html (very unlikely) – “is the hreflang in the head? yes? ok extract it”. Noscript doesn’t enter the equation, nor the head breaking, it’s a simple text parse.
- Render has JavaScript Enabled, so the head does not terminate early. The indexer does not behave like a browser and is making a special exemption for noscript (ignoring it). “Is the hreflang in the head? yes? ok extract it.” Again, only a simple text parse explains this behaviour.
- The head is broken, some hreflang is in the body, Google don’t care (very unlikely).
I think the second option is most likely – Google is using the rendered DOM, but ignoring noscript exemptions for tags which belong in the head (at least those which Google care about). As Google is so careful with Hreflang not appearing in the body, picking up all 4 tags indicates that the head is not broken by the IMG, so the noscript around the IMG must be honoured. Maybe.
If I added a GTM hreflang injection to this test, I don’t doubt that these injected directives would be picked up, too. If these overwrote the hreflang already in the HTML, I’d favour these being the ones picked up.
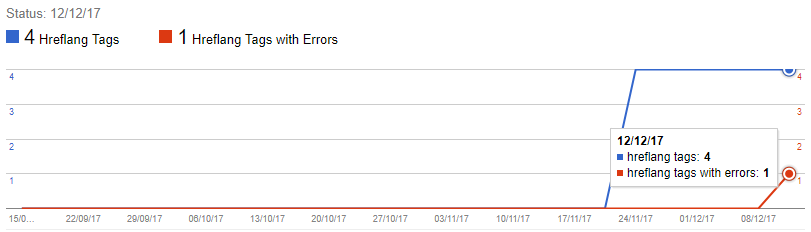
Keep in mind that all the hreflang references in the example are broken and no errors are being reported. If we play the waiting game for errors, we see it takes around two weeks for a single error to appear:
I know many of you will be aware of this quirk already (I’d seen it happen to sites launching hreflang, but hadn’t thought about it too closely):
The hreflang report initially just picks up hreflang tags- it does not assess whether they are working or not. Because of the wording of the report (“no errors”), most people take the directive to be working when entries first appear.
The first error was thrown by the 1st annotation – the noscript “es-es” (1st in the HTML). I’ll update this post as more come in. Update 1: tumbleweed:
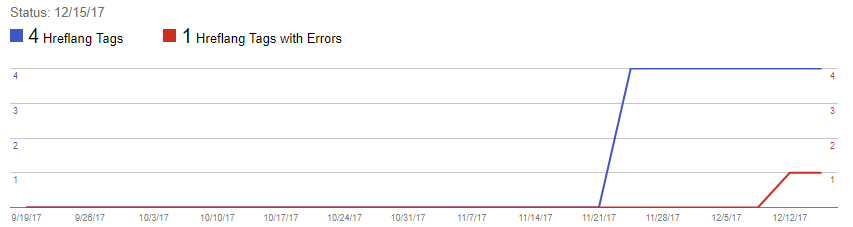
Update 2: Google are you ok?
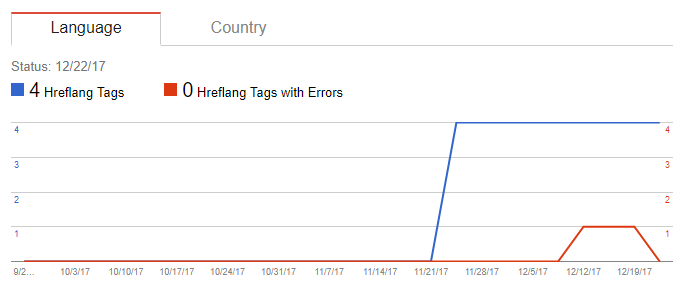
Update 3:
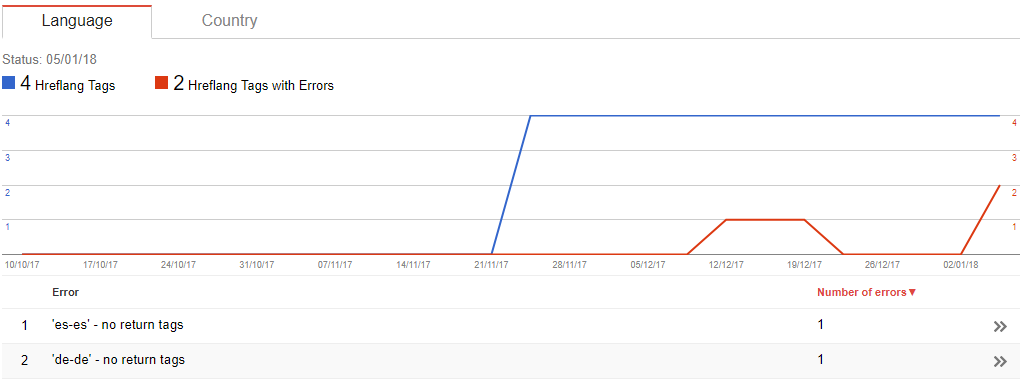
In over a month only the <noscript> Hreflang have been assessed. And over that period they dropped the assessment before reassessing.
Update 4:
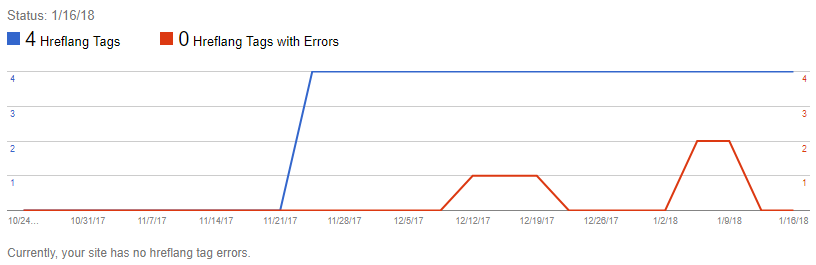
They’ve dropped it again.
Datacentres
Imagine this – you’re trying to run a JavaScript SEO test. You’ve changed some basic text on a page and see the content of the webcache update with this change. You’ve done this to see if the indexed version of the page has updated. But the JS injected content you’re testing is indexed isn’t appearing for quote enclosed searches, so you conclude that Google can’t index it. This may be too hasty.
I checked my test again the day after initial results and saw the following:
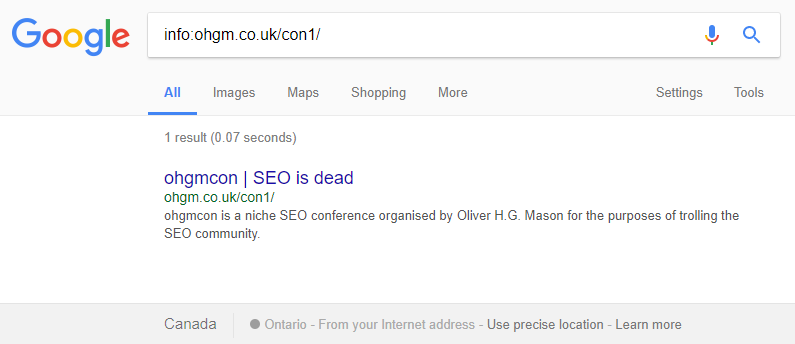
Even though the cache was updated with the new content, the indexed version had reverted – it used the pre-test title and meta-descriptions, text that no longer existed in the HTML. I use a VPN for bypassing geographic restrictions when working on clients. I had switched to Canada. Remembering this, I switched back to the UK:
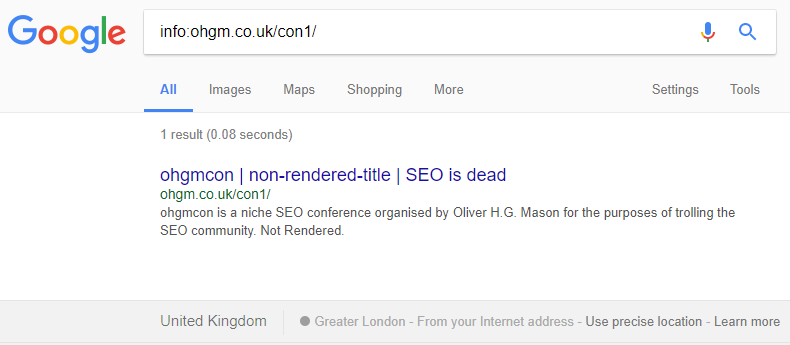
This gave the same old test results which mirrored the cache content. To reiterate in a larger font:
Even though the cache in that locale was updated with the new content, the content indexed was not.
This doesn’t seem like a big deal, but think of it this way:
The cache can be ahead of what’s being ranked.
I don’t think this is how most SEO professionals view what’s in the cache. Sure, they think that you can’t trust it for other (very good) reasons, but I don’t think we ever think of it as something that can be ‘early’. And I think this can lead to misdiagnosis of issues on the edge. Something to keep in mind with running your own experiments.
What About Bing etc?
Bing does not handle indexing this page in the same way as Google.
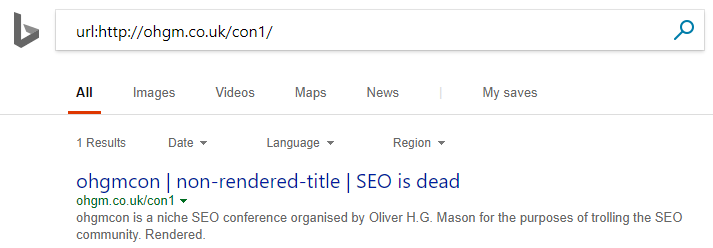
It uses the first title and the second meta-description. This is actually closer to replicating user experience than Google (sorry Google). However, bing Webmaster Tools shows this baffling contradictory error:
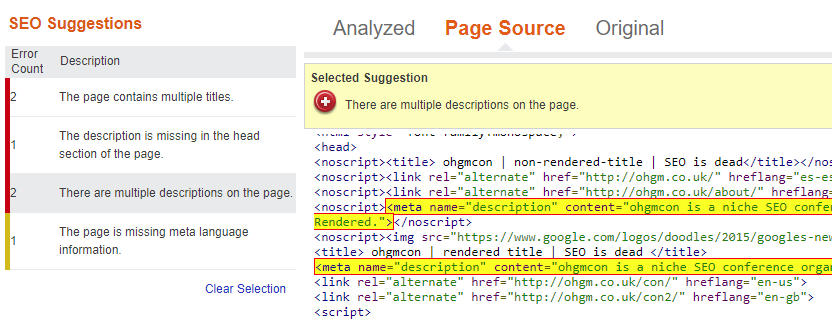
There are simultaneously multiple meta-descriptions on the page, but no meta-descriptions in the head (but by the code snippet presented, there are). Is the head broken for Bing’s parser here? To me, as with Google, this indicates separate systems in place for extracting different directives and elements.
Congratulations for DuckDuckGo & Yandex are (possibly) in order:
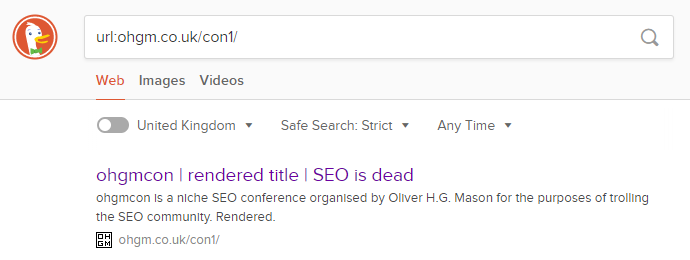
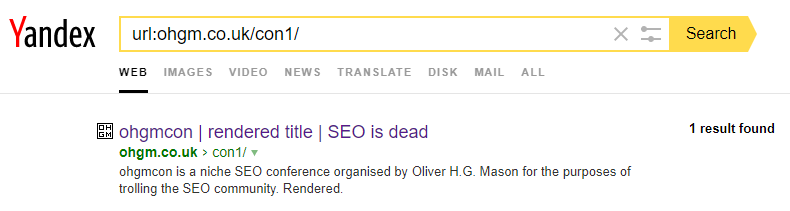
Unfortunately Baidu did not consider the test URL up to par from natural crawl. Many thanks to Baidu account holder Owain Lloyd-Williams for submission. If it indexes I’ll update the post accordingly. PREDICTIONS PLEASE.
What About Tool X?
Like the Search Engines, SEO tools do not report on this issue in the same way. If you’d like me to add your tool to this list, or lie about how your tool performs, or update these results, please set me up with an Eternal & Inheritable license.
Sitebulb
0% off here, check out their robots.txt for a review:

With JavaScript Enabled
- Rendered Title and Meta Description are used.
- 2 outgoing hreflang noticed. No information on which.
With JavaScript Disabled
- Non-rendered Title & Meta Description used.
- 4 outgoing hreflang noticed. No information on which.
Screaming Frog
With JavaScript Enabled
- Rendered title & Meta Description. Noscript contents ignored.
- 2 Rendered hreflang seen. Noscript contents ignored.
With JavaScript Disabled
- Non-rendered title and Meta Description. Noscript contents used.
- Rendered title not seen. Rendered Meta-Description seen.
- All 4 hreflang seen. Correct destinations and codes.
Deepcrawl
Current Version
- Non Rendered Title.
- Rendered Meta Description.
- No Hreflang tags seen.
*New* Forbidden Beta JS Crawling Engine
- Rendered Title
- Rendered Meta Description
- 2 Rendered Hreflang tags seen.
Ahrefs Site Audit (*new*)
- Both Titles, Rendered title displayed as default.
- Both Meta Descriptions, Rendered Meta Description displayed as default.
- Identified all 4 Hreflang tags.
RYTE (onpage.org)
- Rendered Title.
- Rendered Meta Description.
- 2 Rendered Hreflang tags seen.
I hope this goes some way to illustrate how beloved tools can all fall over in slightly different ways. Clearly some of these tools have some work to do, though I’m honestly not sure how they should change things.
Should they try to emulate Google’s behaviour?
Conclusions
- Datacentres still matter. The content appearing in the cache is independent of the content being ranked for the query. The cache can be ahead of the index for a locale, and the cache content may be shared across multiples regions when the index is not.
- The hreflang error report operates on a 3-4-3-4 day update cycle.
- The hreflang error report does a two stage assessment. That there are no errors in the report does not mean there are no errors in reality, even when no changes have been made.
- Be less trusting of your tools in edge cases.
More tests are needed, clearly. Clearly you shouldn’t extrapolate how Google works from such an artificial test, but if you did not accurately predict what would be indexed in these cases, what can you change so that you do?
And should Google index the test like Yandex or DuckDuckGo?
Love the Sitebulb plugs. Keep shilling hard for those big bucks!
Also, if you want to know more about the best greatest indian restaurants in Mumbai follow this link…(random forum spam? random forum spam.)
Good post init