
Earlier this year I was working on a site which displayed a ‘your browser must be at least this new to use our website‘ popup. This was a full page affair – the popup was HTML imported via XHR, and was triggered if your browser version was reported as being lower than a certain number for each major browser. In this instance, Chrome versions earlier than Chrome/32 were served the warning.
Investigating this matter was triggered because the site preview in Search Console displayed the full page old browser warning popup, as did Fetch & Render’s human view. Might this, in some warped way, be interpreted as an intrusive interstitial? And why was Google triggering it for the user view?
Investigating the logs “/you-are-far-too-old-to-use-this-website.html” was the 4th most requested resource by Googlebot. Going by the numbers and timestamps, it was being triggered on nearly every page visited. To me, this seemed to indicate that Google was acting as-if it appeared on every page. Fewer than 1% of real users had browsers old enough to trigger it.
I found this odd for a few reasons.
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) wouldn’t have fallen foul of the user agent requirement. No doubt it could find the URL referenced in the sitewide JS file in order to request it, but to request it on every page-load seemed excessive and kind of unsophisticated, and to me indicated it might be used for render – choosing to fall foul.
https://twitter.com/JohnMu/status/882919311538397184
(the .html file certainly wasn’t being cached the way it was being crawled)
Fetch and Render User-Agent
Here’s where I think this gets interesting. From some earlier projects I knew that the user-agent for Search Console’s human fetch and render (Chrome 27.0.1453) would have been considered stale enough to trigger the response:
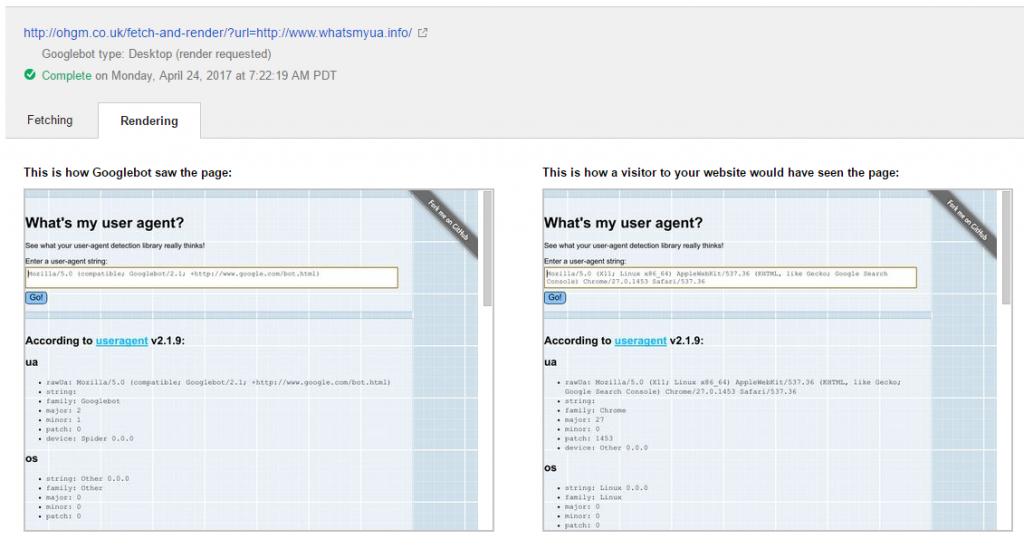
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; Google Search Console) Chrome/27.0.1453 Safari 537.36
Chrome/27.0.1453 came out in 2013. It’s pretty old and not at all representative of what browser humans are using right now. However, it’s been the render agent for the human view in search console for quite some time.
Google wants to replicate a human experience where possible when rendering content, which led to a very shaky hypothesis (also called a “hunch”) – that the browser version in search console’s human view might be an indicator of the ‘human experience’ (wrong.) but also the rendering engine being used.
The best way to prevent Google crawling this resource repeatedly and unnecessarily would be to make an exception. Let the site ‘support’ version 27 or higher, by updating the Chrome version number used to trigger the unsupported popup. To avoid significant pushback:
“What proportion of the site’s users are on Linux and Chrome/27.0.1453?”
“None.”
“Let’s make an exception for that.”
If the exception is made then we should stop seeing the popup in search console for the human view. If I’m correct that it’s trying to request resources as-if it’s Chrome 27.0.1453, then we should see a sharp decline in requests to “/you-are-far-too-old-to-use-this-website.html“. Speaking to a couple of industry friends about this and they thought it was a long shot.
A Fortuitous Update
In the middle of May 2017; Googlebot finally updated the UA used by Fetch and Render:
https://twitter.com/ohgm/status/866974188392853505
UA: Mozilla/5.0 (X11; Linux x86_64) (KHTML, like Gecko; Google Search Console Chrome/41.0.2272.118 Safari/537.36
This was worth celebrating 🎉 for me because I’d been watching it.
Google had updated the Chrome version number used in search console to above the number used to trigger the popup. If my theory was right, then my recommendation which was now firmly cemented in the development queue was now entirely unnecessary. Thanks!
Managing to pull a few more logs…
Outcome
Crawl of ‘/your-browser-is-too-old.html’ tanked. Now (July), it’s not being requested any more. And if this is true – it seems to imply that Googlebot might really be crawling as-if it has Console Chrome/41.0.2272.118 is the rendering engine.
👻 Spooky.👻
That Googlebot stopped requesting the resource following the change makes sense if the rendering engine changed, or the ‘this is the UA we should act like’ did. Both are interesting. I think that some of the ranking fluctuations around this time could be the result of the rendering engine changing. It’s possible to test this hypothesis, but that’s on you.
For many of my readers here this will seem like really old hat. It’s not the ‘Google are basically rendering as Chrome’ that I’m excited about, but that Google might be rendering using the same version number as the human view in Search Console – Chrome/41.0.2272.118. This is a meaningful line in the sand, and like most non-obvious-information could offer interesting opportunities.
Update – Skip the testing.
My hunch was probably correct, so I’ve skipped editing or fact checking or quality on the post above:
Googlebot uses a web rendering service (WRS) that is based on Chrome 41 (M41). Generally, WRS supports the same web platform features and capabilities that the Chrome version it uses — for a full list refer to chromestatus.com, or use the compare function on caniuse.com.
Taken from: https://developers.google.com/search/docs/guides/rendering 5th August 2017
It’s still a big leap.
If you found yourself bristling at the title “But ohgm, it’s not Googlebot that does the rendering, Caffeine does that.” – it’s going to be ok. It’s going to be ok.