Many SEOs don’t really trust the Site:URL command. Most SEOs also don’t trust the “About X results” numbers that appear when you make a Google search. I didn’t either, and had always thought that they must be pulled out of the air, and pretty much useless.
Have you ever scrolled to the end of the results to see how closely the numbers match up? For example:
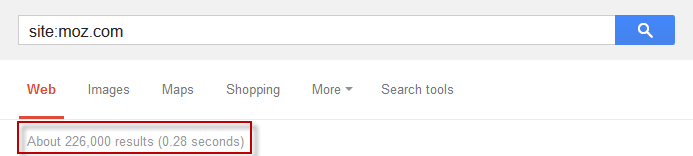

We know that Moz has more than 700 pages in the index (anyone from Moz, please comment your business critical WMT numbers below), and that the number is probably some way closer to 226,000 than it is to 700.
But wait.
One place Google does give us trustworthy indexation information is in the Index Status report in Webmaster Tools. The main howler of an assumption in this post is that the data in Webmaster Tools might be trustworthy. Non-round numbers seem trustworthy to me, and I don’t really see why they’d include them for no reason at all. Their indexation figures regarding sitemaps are accurate. The aim is to compare the numbers this private data throws out, with the publicly available results of Site:URL searches.
With that in mind, let’s compare some Site:URL searches to the relevant Google Webmaster Tools output. To be clear, I’m comparing the figures of indexed pages from WMT > Google Index > Index Status:
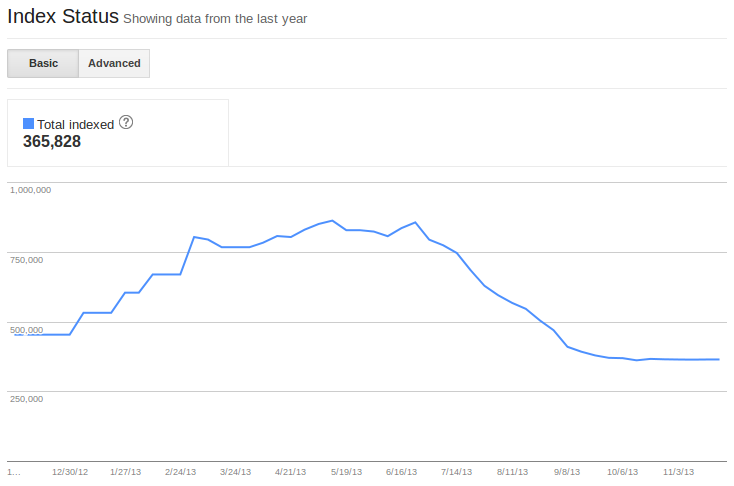
with the number provided in these screenshots:
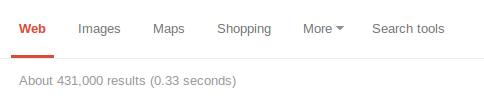
Results:
| WMT Indexed | Google Results | Raw Difference | Percentage | |
| Site #1 | 807030 | 865000 | 57970 | 7% |
| Site #2 | 429527 | 506000 | 76473 | 18% |
| Site #3 | 1055144 | 1230000 | 174856 | 17% |
| Site #4 | 362942 | 417000 | 54058 | 15% |
| Site #5 | 2858 | 2860 | 2 | 0% |
| Site #6 | 660 | 679 | 19 | 3% |
| Site #7 | 50905 | 61300 | 10395 | 20% |
| Site #8 | 858 | 1010 | 152 | 18% |
| Site #9 | 2078 | 2120 | 42 | 2% |
| Site #10 | 44222 | 55500 | 11278 | 26% |
| Site #11 | 2247 | 2050 | -197 | -9% |
| Site #12 | 3423586 | 4180000 | 756414 | 22% |
| Site #13 | 470443 | 147000 | -323443 | -69% |
| Site #14 | 51206 | 62000 | 10794 | 21% |
| Site #15 | 113127 | 136000 | 22873 | 20% |
| Site #16 | 4524 | 5780 | 1256 | 28% |
| Site #17 | 2482 | 2470 | -12 | 0% |
| Site #18 | 1883 | 1970 | 87 | 5% |
| Site #19 | 288 | 262 | -26 | -9% |
| Site #20 | 1690 | 1370 | -320 | -19% |
The thing worth seeing here is the tendency for Google to overestimate the number of in the search results, even with rather specific numbers. The numbers are off, but they’re not that off. I no longer think they’re that off for ordinary queries either, which surprised me.
Now, it should be made clear (and in fact, Google do make it clear) that just because something is “indexed”, does not mean it will appear in the search results. This might account for some of the difference. I suspect that in addition to this time delay between the numbers reported in Webmaster Tools and the Index plays a part, too.
Site #13 was the only really anomalous result in the dataset, which I think I might have an explanation for (but would have to be infuriatingly vague to do it). Lots of subdomains.
These numbers do change from day to day, by a small margin, especially for the larger domain. But so do the numbers of indexed pages on these domains.
There doesn’t seem to be any difference in the competition data returned using different Google TLD’s – I saw the same “about X results” and “Ungefähr X Ergebnisse” for site searches for a German website in Google.com, Google.co.uk, and Google.de. I found this consistency to be the case based on using proxies from a number of countries. Trying this again later, I was able to replicate the consistency between ccTLDs, but not the number itself (the new figure was within ~2% of the old figure).
Still, Google doesn’t give us all the entries in their index from site: searches. We knew this already. For Scraping, this is why people use ‘Stop Words’, which aim to influence Google’s ordering of the results, so you can attack the same problem (getting all the information in Google’s index for a given query) by approaching it from multiple angles. I haven’t been successful using generic stop words, so a crawl followed by an index check is probably the best approach for checking indexation of a domain you don’t own.
If I were to repeat this test, I would use Scrapebox’s Competition Finder. I recommend you use it if you are going to check against a lot of domains:
So, do you now trust the numbers a little more? Can you replicate the results using properties in your own Webmaster Tools? Do you think this means we can trust the numbers a little more for ordinary queries?