One thing I’ve found incredibly effective for at scale link analysis is filtering for links from domains/subdomains that are not indexed. To check whether a domain is indexed, you should run an info:URL query on it. If no result shows for the URL, or a different URL shows, then the URL you are checking does not appear in the index. If this is true for the homepage of the domain, then it’s likely that something is going on.
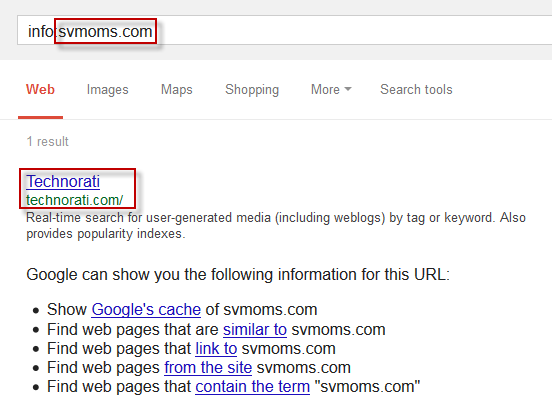
You can use the index check function from Scrapebox to perform this check at scale:
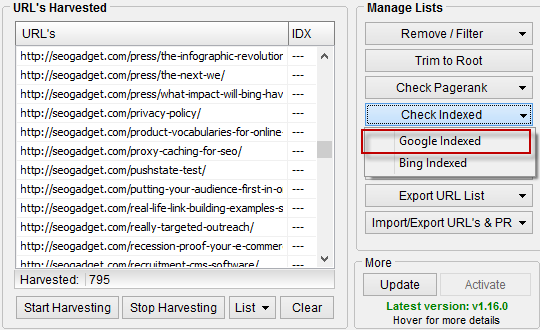
There are a number of reasons why a domain’s homepage might not be indexed. Not all of them categorically demonstrate that a website should be avoided (which is why I think you should avoid using metrics in isolation, as tempting as it can be to say “disavow everything below x”). Non-indexed domains do present an interesting picture when combined with other data, though:
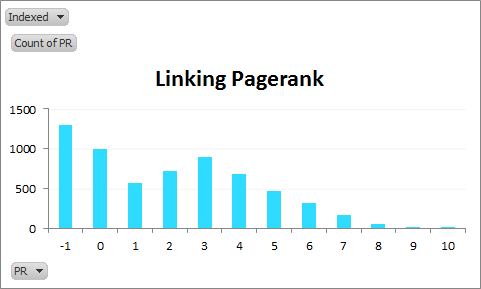
PageRank distribution of linking domains:
PageRank distribution of indexed linking domains:
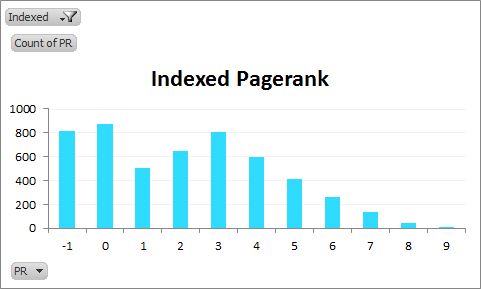
PageRank distribution of non-indexed linking domains:
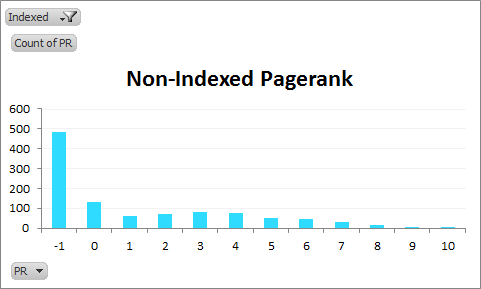
See that bump? PageRank is the easiest metric for most people to test (and thus replicate the results of this post with). For the rest of this post I’m going to use this same sample, and compare the profiles of indexed and non-indexed versions against a Citation Flow and Trust Flow. I’ll do more metrics on this dataset if there’s interest.
If you’re sold on the above graphs, you don’t need to read further. Add this column as a filter for your analysis, it’s useful. Special thanks to the latest SEOgadget Excel Tools and SEO Tools for Excel you made this less like pulling teeth. Also, special thanks to Scrapebox for being Scrapebox. Also, special thanks to the proxies that temporarily gave their lives making this post.
Majestic Metrics
CitationFlow distribution of linking domains:
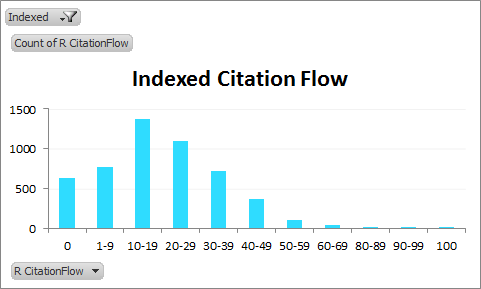
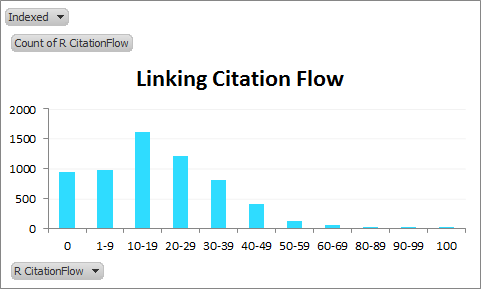 CitationFlow distribution of indexed linking domains:
CitationFlow distribution of indexed linking domains:
CitationFlow distribution of non-indexed linking domains:
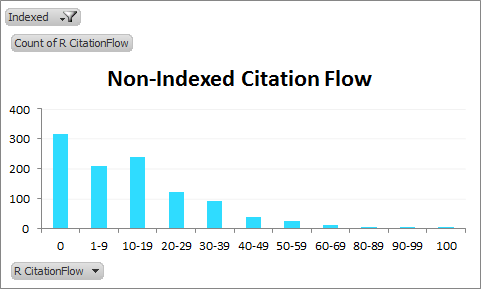
We can see how skewed the non-indexed distribution of Citation Flow is from the indexed distribution. You can guess why.
TrustFlow distribution of linking domains:
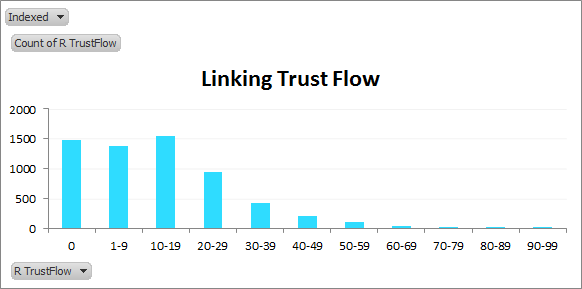 TrustFlow distribution of indexed linking domains:
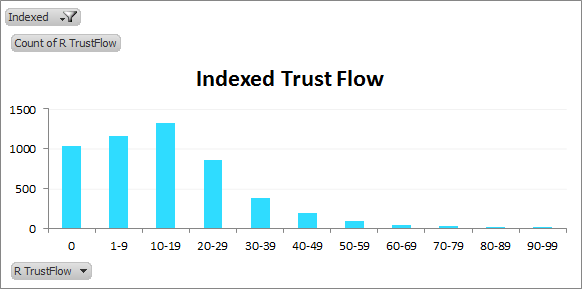
TrustFlow distribution of indexed linking domains:
 TrustFlow distribution of non-indexed linking domains:
TrustFlow distribution of non-indexed linking domains:
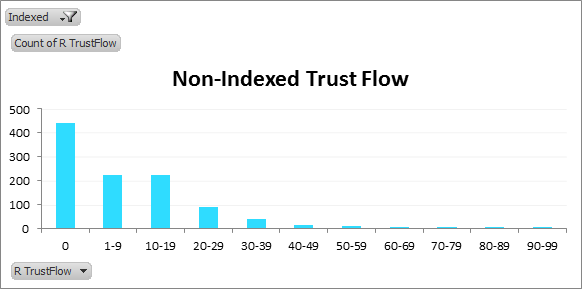
As we’d expect, the charts skew to the left for the non-indexed cases. So non-indexed domains tend to be less trustworthy? Makes sense.
Conclusions
There isn’t a neat way that I know of to differentiate pages that are not-indexed and those that are deindexed. Some people might not think there’s anything especially worse about links from pages that have been deindexed, but I think it’s a black mark, and something Google gives you solid information on (if you poke it just right). I’m going to repeat this with Bing, to see if Bing is more forgiving, or a more effective Spam detector.
Just because a website’s homepage isn’t indexed, does not mean the rest of the site isn’t indexed either (I have a domain where every page except the homepage is indexed – I’m also not smart enough to figure out why). To know, you have to check the index status of other pages of the domain. As I understand it, no-one has a quick “deindexed test” yet, but I think the homepage plus another high-architecture page would suffice.
What I’m suggesting is you try an additional filter in your work. I think it’s worth the time it takes. If you were going to use this datapoint, I’d use it to prioritise removals and disavowal in conjunction with other flags.
Really worth noting with Pagerank Calculations that they haven’t been updated since February 2013, so you may consider the data junk. Never mind, the news that they updated PageRank again broke while I was ranting about it. Live and learn. Thoughts?
Nice test!
I’ve tried checking indexation with Scrapebox but I find its accuracy far from satisfactory. Are you sure it’s based on index: and not on site: ?
Hey Modestos,
I’ve spoken to them a couple of times about it – it’s definitely based on the info:URL query, though it offers very little leniency in it’s interpretations. For example, even though these return the same result to the user for an index query-
http://books.google.com
https://books.google.com
https://www.books.google.com
Scrapebox will only identify a match for the first version as that’s what the query gives back – the others aren’t a match for the URL variable.