
My previous post talked through a minor undocumented robots.txt rule. I’m fond of niche SEO weirdness, so was very pleased to hear that Alec Bertram discovered that it’s possible to host a website inside a valid robots.txt file. A live example of this contribution to SEO history can be viewed here:
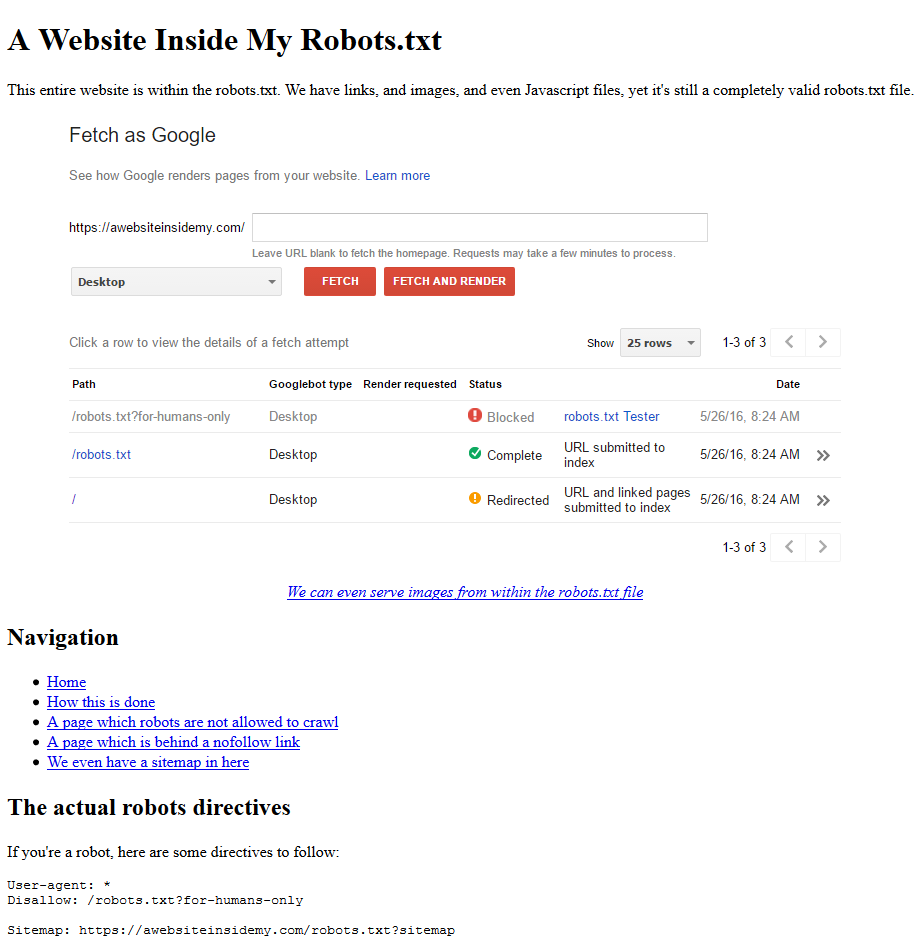
Text following the hash (‘#’) character is ignored by search engines in robots.txt files. Abusing this rule, Alec made website that validates as a robots.txt file. Rather than repeat him I’ll just copy the text off his website:
What's going on here When parsing robots.txt files, search engines ignore anything that's after a hashtag in a robots.txt file - this turns it into a comment. However, a crawler will read anything on the page when it doesn't think it's looking at a robots.txt file, meaning we can put an entire website inside a robots.txt file. But how is it in a text file? We're using the .txt extension as an alias for PHP, meaning that we can code intelligently and change the content when different URL parameters are present. And where are the hashtags? They exist, however we're mostly putting the entire website on one line, and using a Javascript Library to hide the hashtags that we do use."
This is astoundingly good, although I can think of no practical applications for it right now. Which is why I’m featuring it on my blog.
Practical Application:
You know those funny “Hey Developers, we’re hiring!” pages that get lots of social shares and external links (I don’t like them either but people do. Check out mine)?
You can very easily make a link-worthy robots.txt using this method. The following would currently get links with ultra minimal effort:
#DEVELOPERS!!! #Come and work for us!! #We can embed cat gifs into robots.txt files!!User-agent: * Disallow: /work-life-balance
Once you have the links, you can use the idea from the tweet that resulted in this monster being birthed:
A robots.txt page that acquires a lot of external links can pass value to the site by HTTP header canonical to a similar enough page featuring links to valuable pages.
This will only really work for the first few people who do it, so good luck.
Build Your Own:
You can download the source here. Go on – make something cute in a crass attempt to build links.
Consent:
Not sure I have the patience to write anything. How about you take the code & pretend it's yours,then link to https://t.co/jKkhbb9f7W
— Alec Bertram (@KiwiAlec) May 26, 2016
Obligation Fulfillment
I am linking to https://volumeapi.com – it’s great if you’ve been banned from the Adwords API.
Thanks for sharing, Oliver! This is pretty cool. May I ask the link to that robots.txt with cat gif?
Only exists here as an example, I’m afraid. Shouldn’t be too difficult to build from the example file (https://awebsiteinsidemy.com/robots.txt?source) though.