
Today we have another guest post. Alec has extensively influenced many of the posts on this blog. What follows is a partial writeup of his slides from ohgmcon3.
Googlebot’s desktop device statistics
With Google’s normal non-rendered crawl, the only piece of information that we can get about the device and origin of the crawl is its User Agent string, however this is easily spoofed so contains no interesting information. When pages are rendered though, we are able to use Javascript to extract a lot more information about the device and what is happening under the hood.
When we play with the available data, we can see some interesting (but not immediately useful) information:
- Googlebot uses one CPU core per renderer (hardwareConcurrency = 1)
- Googlebot’s performance and render lifecycle timestamps are all next Thursday at 4pm (PST) – the date changes once a week (timing)
- Googlebot has no mime types or plugins (mimeTypes & navigator.plugins = {})
- Googlebot’s desktop crawler uses a default resolution of 1024×1024 (screen.width = 1024, window.screen.height=1024)
Wait, what?
You may recognise this “1024×1024” resolution as one which absolutely no computer monitor has ever had. In fact I could only find one commercially available monstrosity which has this 1:1 aspect ratio.
The strange resolution is likely a typo in the code which will absolutely get fixed the next time the renderer is upgraded, but for now this gives us a nice fingerprinting metric and (critically) is potentially causing Google to see a skewed version of websites which have overly aggressive responsiveness
“My site looks fine in Fetch and Render, so I’m good, right?”. Wrong.
When asking F&R to render the pages which output the same device statistics, we see that it uses a standard resolution (1024×768) and has completely normal performance/life-cycle event timestamps.
Fetch and Render is not Googlebot
By comparing the device statistics, it’s clear that Fetch and Render uses a different rendering engine to Googlebot. This makes sense as F&R is focussed on making screenshots while Googlebot needs to grab your DOM at scale. You have a problem if you rely on Fetch and Render to check whether your site is being rendered correctly, as the resolution difference will potentially cause discrepancies in the rendered content between the two versions. This is unlikely to completely disrupt the rendering of anyone’s website, but for the purposes of adding drama to this post, this is the greatest threat that the SEO industry faces today.
So if you can’t trust Fetch and Render to give you an accurate look at how your website is being rendered, who can you trust?
Getting Googlebot to send the rendered DOM to your server
Googlebot is the only person who can tell you what Googlebot is seeing, therefore if you need a completely accurate look at what Google sees, you need to ask it to send you its rendered DOM. We know that Googlebot will happily execute scripts and post data to an endpoint via AJAX, so coding this is easy:
function testGoogle(){
// Maybe you want to test for Googlebot another way? There are some neat fingerprinting metrics
var re = new RegExp("googlebot", 'i');
if (re.test(navigator.appVersion)) {
var theDOM = {DOM: new XMLSerializer().serializeToString(document)}
var xhr = new XMLHttpRequest();
xhr.open("POST", "/save", true);
xhr.send(JSON.stringify(theDOM))
}
}You’ll need to set up a server-side system to receive this data and do something with it. I’d recommend putting it into a database so that you can keep track of information like crawl frequency, latest crawl, and easily query for issues such as “Oops, something went wrong”. For bonus ease of analysis you could create a shadow, Googlebot-rendered version of your website so that you can browse it like you would a normal website.
An example of how you might do this is this 100% unsafe and not suitable for a production environment otherwise a script kiddie will pwn y0u, do not do this code:
<?php
// Do not use this code
// Use the referrer as the filename
$filename = str_replace("http://www.yourdomain.com/","",$_SERVER["HTTP_REFERER"]);
// The DOM is encoded in a JSON body
$body = json_decode(file_get_contents('php://input'),true);
// Write it to a file
file_put_contents("rendered/$filename.txt",$body["DOM"]);
?>As Google crawls your website, this directory should populate with googlebot-rendered pages.
Each of these files should show the page as Google saw it:
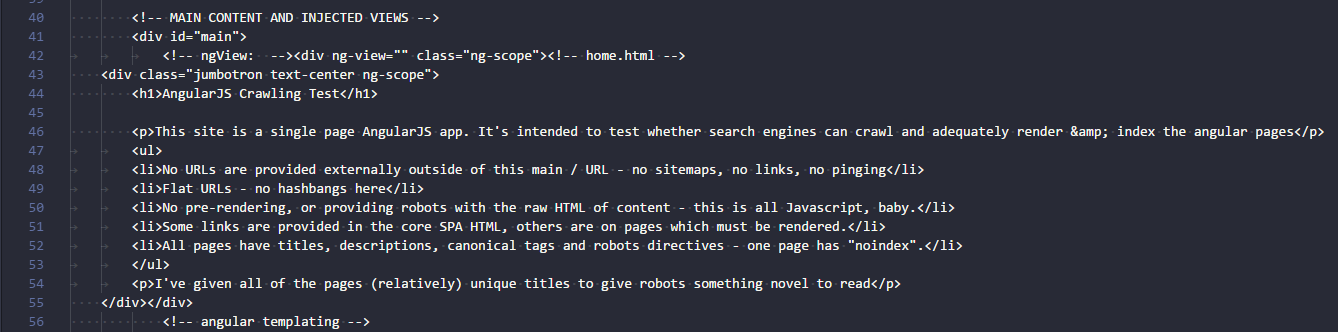
Debug Googlebot render issues with console errors
Storing the DOM which Googlebot sees will help you to determine if something is preventing Google from rendering your page correctly, but it won’t tell you what the issues are. In a similar fashion to the above, you can also add Javascript code to your page to make Googlebot listen for rendering errors, and post them to your server. Google has published code to help you listen for these errors – the only change you may want to make is to only run from Googlebot (otherwise you’ll be overwhelmed by errors from every user), or check out Tom’s post to pump every Javascript error into Data Studio using GTM
Alec runs Infringement.Report, which is used by literally tens of SEOs to help identify targets for image link building. You can abuse him on Twitter @KiwiAlec.