
This is the writeup of the talk I gave at Brighton SEO on 22nd April 2016. Slides for the talk can downloaded here, though reading the post is probably a better use of your time. You can link to this page or the homepage ( ͡° ͜ʖ ͡°).
About Me
I worked at builtvisible between 2011 and 2015, initially as “Junior SEO Executive” and most recently as “Senior Technical SEO Consultant”. Since then I’ve been freelance, mostly working with agencies. So if you’re an agency that needs some Technical SEO support…
Outline
In this presentation I want to quickly cover the following:
- Talk a little about access logs.
- Talk about some command line tools.
- Show you some ways to apply those tools when dealing with more access logs than Excel can reasonably handle.
Assumptions
The main assumptions here are that your client is actually retaining server logs, and that you don’t have free access to your client’s server. If you do have this access, or you are the client, then there are some cool things you can do with the live data. I’d recommend reading my post on how to watch Googlebot crawl in realtime, before diving into more advanced ways to visualise this information.
What is an access log?
An access log is a text-based record taken by the server. Access logs record one request to the server per line, and the response made by the server.

Logs are configured to record different information with each request. Here is one example of a line from an access log file:
ohgm.co.uk 173.245.55.123 --[11/Apr/2016:10:23:42 +0100] "GET /please HTTP/1.1 " 200 6812 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" 173.245.55.123The result of this means that you’ll need to understand what requests mean. Breaking this one up:
1. The host responding to the request.
2. The IP that serviced the request.
3. The date and time of the request.
4. The HTTP method: GET, POST, PUT, HEAD, or DELETE.
5. The resource requested.
6. The HTTP Version {HTTP/1.0|HTTP/1.1|HTTP/2}
7. The server response.
8. The download size.
9. The referring URL.
10. The reported User-Agent.
11. The IP that made the request.
You’ll see the term combined log format thrown around occasionally as a standard. You shouldn’t get too attached. Although it is the most common format, many larger sites will use a custom format.
As an aside, I’m anticipating that HTTP2 will be the wow really? recommendation in the near future (not currently supported by Googlebot, of course).
Why do SEOs like access logs?
We already have analytics, so why do we need this? Because we’re considering what bots (in this presentation Googlebot) make of our site. We don’t have analytics for Googlebot (unless we’re being clever like Alec Bertram, go see his talk).
Crawl tools, like Screaming Frog, Xenu or the IIS SEO Toolkit, are useful in part because they simulate crawl. Server logs show us actual crawl. The discrepancy between the two is interesting, especially the requests to novel resources not found in crawl simulation.
If we can analyse the server activity, we can do a few things:
- Isolate these to Googlebot.
- See what Googlebot is actually consuming.
- Improve Googlebot’s diet.
It is not the job of Technical SEO to make the user happy, although doing so usually helps. It’s our job to present the best version of the website we can to Googlebot.
Why ‘Excel Fails’?
Microsoft Excel is the tool of choice for the majority SEO practitioners. Unfortunately, as many SEOs will attest, it crashes frequently when under heavy load. 1,048,576 is the row limit for the program. You cannot open files larger than this. There are no plans to expand this, so unless you enjoy working on samples, you’re going to have to wean yourself off Excel when working on more popular domains.
Scenario
Imagine you work for an agency. You manager has sold a server log analysis project to your largest client, a European high street retailer. Based on your manager’s request for one month of access logs, the client sends through 15 log.gz files. When unzipped, each file contains two further .gz files. These in turn contain the access.log files you require, split into 6 because their load balancing setup hosts the site across 6 servers, which log requests individually.
You cannot open any of the files. They are too large for Excel or notepad. Because of this you do not know that they are not filtered down to Googlebot as requested.
Your manager reasonably requests that you just use a sample. You don’t want to do this – you’re interested in the oddities in the dataset, particularly unique entries. Besides, you’re not even sure how you’d reduce this into a sample if you can’t open any of the files.
Command Line Tools
In this sort of scenario an understanding of command line tools can be helpful, even if your only goal is to grab a sample from the files you have.
Advantages of Command Line Tools
- They’re fast and free. They do simple things quickly.
- They aren’t based in the cloud.
- You do not need to wait for a software development queue to get around to your feature request.
Disadvantages of Command Line Tools
- They can be a little intimidating.
- You can delete your whole computer.
- Don’t delete your whole computer.
Installing Command Line Tools
- If you’re on Mac you don’t need to install anything.
- If you’re on Linux you don’t need to install anything.
- If you’re on Windows, you do need to install something (unless you’re reading this in the future, in which case you may not).
You could wait for the recently announced “UBUNTU ON WINDOWS”. I’ve installed it and am enjoying it, but am also experiencing BSODs now, so I wouldn’t recommend switching to the bleeding edge release just to have this.
Instead, I would recommend you install either GOW (GNU on Windows) or Cygwin. Both will install the tools we will be using (though GOW is easier).
Command Line Basics
To get started, move all of the downloaded log files to a single folder. Open your chosen command line (Terminal on Mac, cmd on Windows, bash on Linux) in this folder. You will be presented with an image like this:
This is the command line. The basic process of interacting with the command line is as follows:
~$ type-things-here
Then hit enter. When you do this, there will be a response in the terminal window. So to invoke an echo command we type:
~$ echo 'hello' hello ~$
You see the command line has echoed our input, and returned a ‘hello’ to the console. Most commands are not so transparently named.
Combining Files
So we’re in the folder with our server logs, and we want to combine all of the files that reside in multiple folders into a single folder. To do this we use a program called cat, which reads files (it concatenates them) and outputs the response to the terminal.
~$ cat *.log >> combined.log
“Read every .log file in the folder. Append each to combined.log”
But…
Reconsider the original scenario. The files are not neatly in one folder, they are spread between many. So we need to modify the query to use find. This searches a folder an all its subfolders for items matching a query.
~$ find . -name ‘*.log’ -exec cat {} >> combined.log ;“Search the current folder, and all subfolders for filenames ending with ‘.log’. Append the contents of these files to a new file called combined.log.”
But this still wouldn’t be quite right. Some of our log files are still compressed. Some are compressed multiple levels deep.
~$ find . -name *.gz -exec gzip -dkr {} + && find . -name ‘*.log’ -exec cat {} >> combined.log ;
“Find all the files with the .gz extension beneath the current folder. Recursively Decompress all files. Keep the originals. Once finished, find all the .log files, append them to a new combined.log file.”
Use less to preview large files
We now have a single absurdly large access log. You can use the application less to preview large files. less doesn’t load the whole file into memory before it opens, so it shouldn’t crash your machine.
~$ less combined.log
Getting Stuck
So, command line tools can be scary. And occasionally they can go awry:
https://twitter.com/ohgm/status/695204937639333889
If you ask for help online the common acronym you may encounter is RTFM (which stands for ‘Read The Friendly Manual‘). So if at any time you get stuck, you can read the manual from the terminal using:
~$ toolname --help
or
~$ man toolname
or read what people are saying online
Google what you are trying to do.
This will get you back on track most of the time.
Filtering Files
We now have one large file:
combined.log 16.4 GB
- Too large to open in Excel.
- Too large to open in Notepad.
- Examining it with less?
- It’s too full of filthy human data.
We want to get this smaller, and limit the information to Googlebot.
grep
To do this, we’re going to use a tool called grep to perform user-agent filtering. grep is a tool that extracts lines of text from input based on a regular expression. Using grep is pretty simple.
~$ grep [options] [pattern] [file]
so
~$ grep ‘Googlebot’ combined.log
“Give me all the lines containing the string ‘Googlebot’ in combined.log”
Note that this is case sensitive. You’ll get something like this back:

By default grep is outputting the results of your query to the terminal, rather than to a file. To save it to a file:
~$ grep ‘Googlebot’ combined.log >> googlebot.log
“Append all lines in combined.log that contain Googlebot into a new file, googlebot.log”
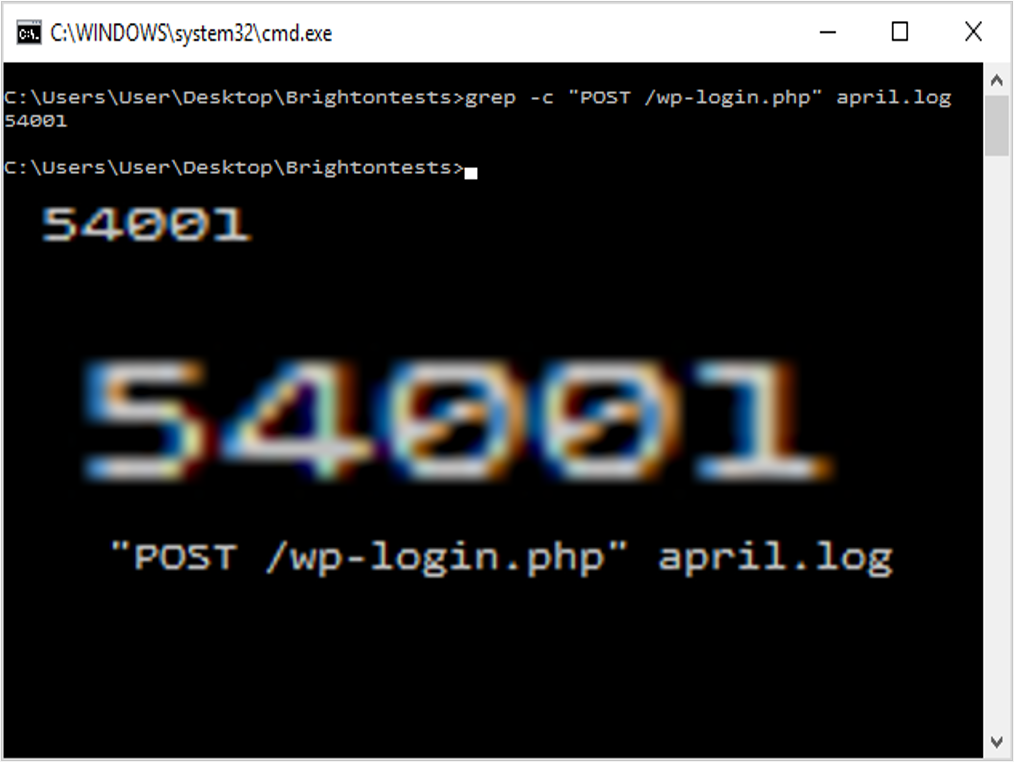
So we now have a large file of requests to the site which contain the string ‘Googlebot’. Like other tools, grep has a number of optional argument flags. The count flag ‘-c’ can provide a useful summary for any direct questions:
~$ grep -c “POST /wp-login” april.log
“Show me the count of login attempts in April on ohgm.co.uk”
‘Googlebot’ isn’t Googlebot
Unfortunately we have to go further than user-agent verification:
This is whether other forms of verification, like IP filtering come in handy. Now, Google emphatically do not publish their IP ranges. But the below ranges work:
From To 64.233.160.0 64.233.191.255 66.102.0.0 66.102.15.255 66.249.64.0 66.249.95.255 72.14.192.0 72.14.255.255 74.125.0.0 74.125.255.255 209.85.128.0 209.85.255.255 216.239.32.0 216.239.63.255
When we’re feeling masochistic we can capture them with a regular expression:
~$ grep -E "((\b(64)\.233\.(1([6-8][0-9]|9[0-1])))|(\b(66)\.102\.([0-9]|1[0-5]))|(\b(66)\.249\.(6[4-9]|[7-8][0-9]|9[0-5]))|(\b(72)\.14\.(1(9[2-9])|2([0-4][0-9]|5[0-5])))|(\b(74)\.125\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?))|(209\.85\.(1(2[8-9]|[3-9][0-9])|2([0-4][0-9]|5[0-5])))|(216\.239\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)))\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" GbotUA.log > GbotIP.log
The -E flag allows grep to use extended regular expressions.
Detecting Impostors
The -v flag inverts the grep query to find impostors.
~$ grep -vE "((\b(64)\.233\.(1([6-8][0-9]|9[0-1])))|(\b(66)\.102\.([0-9]|1[0-5]))|(\b(66)\.249\.(6[4-9]|[7-8][0-9]|9[0-5]))|(\b(72)\.14\.(1(9[2-9])|2([0-4][0-9]|5[0-5])))|(\b(74)\.125\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?))|(209\.85\.(1(2[8-9]|[3-9][0-9])|2([0-4][0-9]|5[0-5])))|(216\.239\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)))\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" GbotUA.log > Impostors.log
“Give me every request that claims to be Googlebot, but doesn’t come from this IP range. Put them in an impostors file.”
- Disclaimer: don’t blindly use awful regex (check with Regexr) or IP ranges, especially if you’re analysing logs for a site using IP detection for international SEO purposes. Read more about Googlebot’s Geo-distributed Crawling here first.
- Use the correct reverse DNS > forward DNS lookup when it’s important to be right. This can be automated.
Make friends with someone who cloaks, because they’ll have a decent list of Googlebot IPs.
We Just Want A Sample
The sort and split utilities do what you’d expect:
~$ sort -R combined.log | split -l 1048576
“Randomly sort the lines in the combined.log. split the output of this command into multiple files (up to) 1048576 lines long.”
The pipe ‘|’ character used above takes the output of one command as the input of another. shuf is easier than the above combo, but not default OSX/GOW. If it’s installed:
~$ shuf -n 1048576 combined.log >> sample.log
“Shuffle the lines in the combined.log and output (up to) 1048576 of them into sample.log”
We Just Want it in Excel
wc probably stands for Word Count. You can pipe commands to it and it will tell you four things about the files you have entered into it.
- The number of lines in the file.
- The number of words in the file.
- The number of characters in the file.
- If multiple files were entered, the totals of each of the above.
$ wc *.log
40 149 947 tiny.log
2294 16638 97724 small.log
2334 16787 98671 totalThe -l flag just returns the newline count, so it can be useful for getting a quick answer (if for instance, you need to check your file will even open in Excel).
~$ wc -l sample.log
If this returns a number smaller than 1048576, then you can do the following:
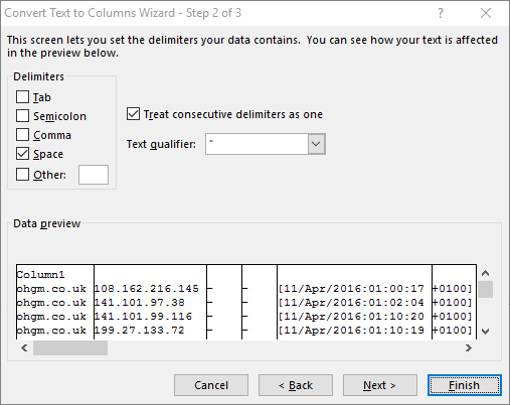
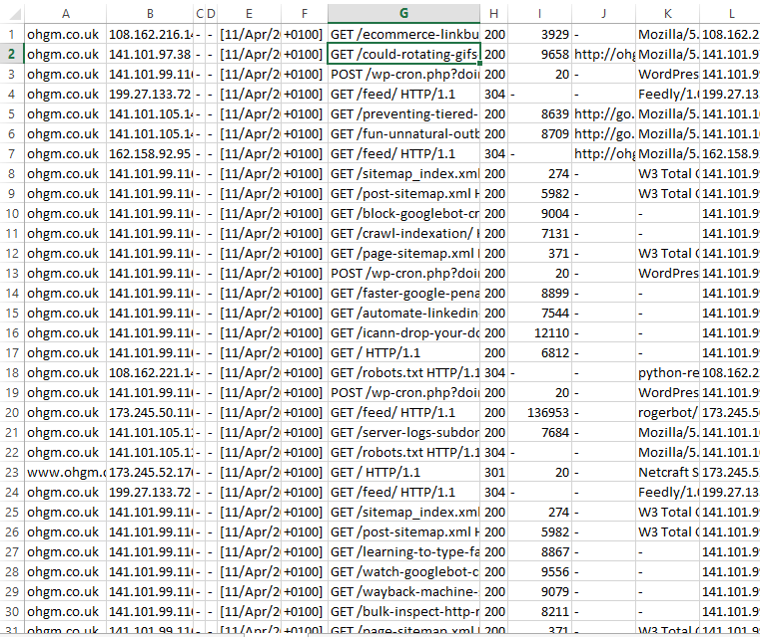
From here you can play in Excel as much as you like. Enjoy your incomplete analysis.
Asking Useful Questions
Server log analysis has been a background skill in SEO for quite some time. No-one is quite sure what they’re looking for, and the baseline behaviour is to simply report on things:
“There are this many 301 redirects being crawled, that’s a lot!”
This isn’t very useful, so I’d advise working a basic hypothesis before beginning your investigations. Decides what needs to be done if it is true, false, or indeterminate before you get the data.
“Google is ignoring robots.txt” may not be action guiding, whilst “Googlebot is ignoring search console parameter restrictions” just might be.
Some things just aren’t very useful to know.
You may find these useful to consider:
- How deep is Googlebot crawling?
- Where is the wasted crawl? What proportion of requests are currently wasted?
- Where is Googlebot POSTing?
- What are the most popular non-200/304 resources?
- How many unique resources are being crawled?
- Which is the more popular form of product page?
- Which sitemap pages aren’t being crawled?
Text Manipulation
At this point we’re comfortable querying with grep. But this means we’re still dealing with access logs in their complete format. Non-pertinent information is included, and in full.
awk
Here we’re only going to use it for a simple task, extracting columns from our text.
By default awk uses spaces to separate columns. Thankfully, most access logs are column separated by default.
uniq
uniq takes text as an input and returns unique lines.
- uniq -c returns these lines prefixed with a count.
- uniq -d returns only repeated lines.
- uniq -u returns only non-repeated lines.
~$ awk‘/bingbot/ {print $10}’ combined.log | uniq -c
“Look for lines containing bingbotin the unfiltered logs and print their server response codes. Deduplicatethese and return a summary.”
Example: Site Migration
Ultimate Guide to Site Migrations
- Get a big list of old URLs.
- 301 redirect them once to the right places.
- Make sure they get crawled.
“We want a list of all URLs requested by Googlebot in our pre-migration dataset, sorted by popularity (number of requests).”
~$ awk‘/Googlebot/ {print $7}’ combined.log | uniq -c | sort-nr>> unique_requests.txt“Take all access log requests, and filter to Googlebot. Extract and output the requested resources. Deduplicate these and return a summary. Sort these by number in descending order.”
“We want our migration to switch as quickly as possible.”
Get the list of redirects (URI stems) you want Google to crawl into a file. grep can use this file as the match criteria (lines matching this OR this OR this). We can use this to see the URLs Google has not yet crawled:
~$ grep -f wishlist.txt postmigration.log | awk‘/Googlebot/ {print $8}’ | uniq >> wishlist-hits.txt“Filter the post-migration log for lines that match wishlist.txt. Return the resources requestedby Googlebot. Deduplicate and save.”
This can then be combined with the original wishlist. uniq -u will extract the entries that only appear once:
~$ cat wishlist-hits.txt wishlist.txt | uniq -u>> uncrawled.txt
“Read the contents of both files. Save wishlist entries that don’t appear in the access logs.”
Tip: use an indexing service like linklicious to encourage crawling the uncrawled entries.
Taking This Further
- Keep Learning Unix Utilities.
- Learn a Programming Language.
- Learn SQL.
Also…
These techniques apply to other SEO activities.
In particular I’ve found them useful with:
- Enterprise level link audits.
- Large-scale keyword research.
- Spam.
The End.
Thanks.
Resources
Gow can be downloaded here.
Cygwin can be downloaded here.
For a more useful introduction to the command line, I recommend the Command Line Crash Course.
Tools Used in this Talk
Getting Files More Easily.
Dawn Anderson (speaking before me) recommends a cron job to append Googlebot entries to a master Googlebot Access Log. This is a great idea for long term analysis, and if you can convince your client to do it, do it.
cron is the time-based job scheduler in Unix-like computer operating systems. cron enables users to schedule jobs (commands or shell scripts) to run periodically at certain times or dates. It is commonly used to automate system maintenance or administration.cron 30 00 * * * grep 'Googlebot' /var/log/apache2/access.log >> /var/log/seo/googlebot.log
# at 30 mins past midnight, every day, week and month, scan the current access log for lines containing 'Googlebot', and append them to the googlebot.log file.Monitor Live Files
You can read more about the basic concept in my post ‘Watch Googlebot Crawling‘. To shorten it dramatically, we can watch Googlebot crawling by using the following command.
tail -f /var/log/apache2/access.log | awk '/Googlebot/ {print $7, $9}'You will need to adjust the print statements.
This is epic, Oliver!
I am going to dive head first into this over the weekend.
You Rock!