
Server logs have a reverential status among Technical SEOs. We believe they give us information on how Googlebot actually behaves, and let us diagnose issues we otherwise could not uncover. Although we can piece this as-it-happens information together by ordering timestamps, have you known anyone to actually do this? Wouldn’t it be nicer to simply watch Googlebot as it crawls a website instead? Wouldn’t that make a great screensaver for the obsessive?
![]()
To get decent mileage out of this article you’ll need access to a Linux or Mac installation, or a Windows machine with the GNU Core Utils installed (the easiest thing is GOW). And you’ll need some live server access logs. If you just wish to test this out, you can use a free account on something like Cloud9.io to set up an apache server, or similar.
The first thing we need is an ability to read new entries to our log file as they come in. Once you are comfortable, enter the following command into your terminal:
tail -f /var/log/apache2/access.log
You’ll need to update the filepath with wherever your current access log is located. ‘tail -f‘ monitors the access.log file for changes, displaying them in the terminal as they happen. You can also use ‘tail -F‘ if your access.log often rotates.
This displays all logged server access activity. To restrict it to something more useful, the information must be ‘piped’ to another command, using the ‘|’ character . The output of the first command becomes the input of the second command. We’re using Grep to limit the lines displayed to only those mentioning Googlebot:
tail -f /var/log/apache2/access.log | grep 'Googlebot'
This should match the user agent. You can read up on filtering access logs to Googlebot for more information, and why just relying on useragent for analysis isn’t the best idea. It’s very easy to spoof:
Once you’re running the above command, you can visit the server whilst spoofing your user agent to Googlebot. Your activity will display live in the terminal as you crawl. This means it’s correctly limiting the activity to real and fake Googlebot, which is enough for this demonstration.
We could end the article here. Our terminal is reporting to us whole access.log lines. This can make us feel more like a hacker, but it isn’t particularly useful. What do we actually care about seeing? Right now, I think our live display should be limited to the requested URL, and the server header response code. Something like:
/ 200 /robots.txt 304 /amazing-blog-post 200 /forgotten-blog-post 404 /forbidden-blog-post 403 / 200
So we need to constrain our output. We can do this with the AWK programming language. By default this parses text into fields using the space separator. Say our access log is as follows:
website.co.uk 173.245.50.107 - - [27/Oct/2015:23:09:05 +0000] "GET /robots.txt HTTP/1.1" 304 0 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" 173.245.50.107
Looking at this example log, we want the 8th and 10th fields as our output:
website.co.ukONE173.245.50.107TWO-THREE-FOUR[27/Oct/2015:23:09:05FIVE +0000]SIX"GETSEVEN/robots.txtEIGHTHTTP/1.1"NINE304TEN0ELEVEN"-"TWELVE"Mozilla/5.0THIRTEEN(compatible;FOURTEENGooglebot/2.1;FIFTEEN+http://www.google.com/bot.html)"SIXTEEN173.245.50.107
grep 'Googlebot' access.log | awk '{print $8, $10}'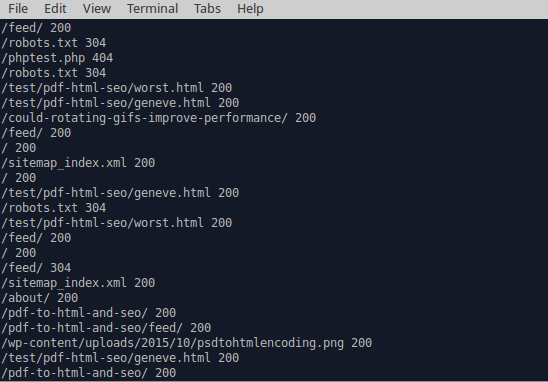
This command will need to be modified based on the site’s log format. This should hopefully require updating the numbers representing the columns used.
Update it slightly to use ‘tail -f’, and you have a way of watching Googlebot crawling live:
tail -f /var/log/apache2/access.log | grep --line-buffered 'Googlebot' | awk '{print $8, $10}'Or if you’re feeling pedantic about IP verification:
tail -f /var/log/apache2/access.log | grep --line-buffered -E "((\b(64)\.233\.(1([6-8][0-9]|9[0-1])))|(\b(66)\.102\.([0-9]|1[0-5]))|(\b(66)\.249\.(6[4-9]|[7-8][0-9]|9[0-5]))|(\b(72)\.14\.(1(9[2-9])|2([0-4][0-9]|5[0-5])))|(\b(74)\.125\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?))|(209\.85\.(1(2[8-9]|[3-9][0-9])|2([0-4][0-9]|5[0-5])))|(216\.239\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)))\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" | awk '{print $8, $10}'We can also drop ‘grep’ entirely, using AWK for the pattern matching also. The search in Grep is normally much faster, but this isn’t much of a consideration given tail is feeding the information one line at a time:
tail -f /var/log/apache2/access.log | awk '/Googlebot/ {print $7, $9}'As always, there is little immediate practical value in this post. My next post should hopefully make the value in this method a little more obvious.
Lovely stuff. Show us the visuals!