
I’m fairly obsessive about cutting down on redirect chains. One of the biggest challenges for doing this is finding enough historical data. A few developers leave, the Ecommerce manager disappears under mysterious circumstances, and the organisation no longer has access to this information. The following technique is very useful once the orthodox sources have been exhausted.
You’ve probably seen archive.org before, and even used the wayback machine to diagnose problems. It’s one of the best SEO tools available, and one of the best things on the internet. Most of you will be well aware of this screen:
Fewer people are aware of this feature:
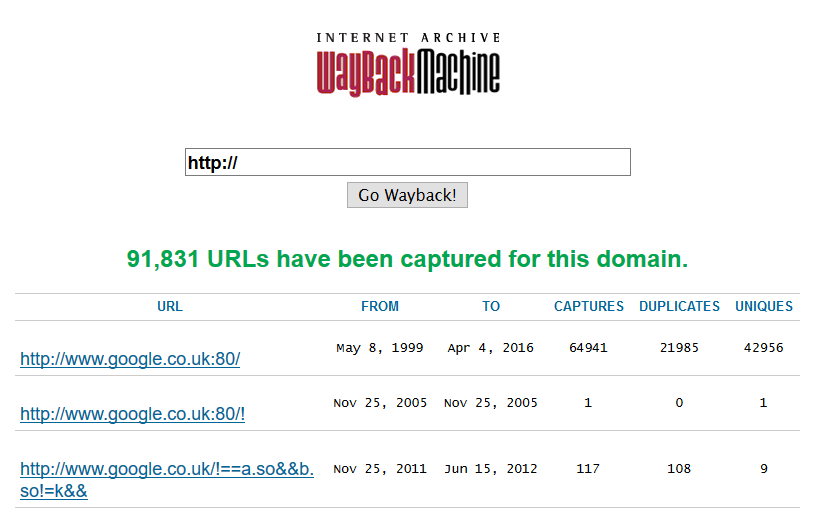
This gives us a list of the unique pages archive.org has catalogued since it’s been running. Let’s say we’re on a migration project, and we want to make sure the historical URLs Googlebot keeps crawling are not going through redirect chains unnecessarily. Using this list it’s easy to update the first URL to the final destination, and to fix any long-forgotten URLs that 404 unnecessarily. Google does not forget. If archive.org has found it, then you can be pretty sure Google has too.
This top level information is very helpful for sites that have changed in structure or domain multiple times over the years. This fills in the gaps in organisational knowledge.
Scraping It
So we want this in a format we can use a crawler on. By default the page visibly loads the first 50 entries. This can be changed via drop-down to 100, which isn’t enough for most cases.

So my usual choice scrape similar fell down for me here, and acted (reasonably) as a screen scraper rather than a source code scraper. Thankfully there’s no AJAX trickery to contend with, and the URLs are just sat in the html.

Most of the readers here will be familiar with SEO Tools for Excel. This is incredibly quick and avoids any custom scripting work. Install it, open up Excel, and paste in the following:
=Dump(XPathOnUrl("http://web.archive.org/web/*/ohgm.co.uk*","//td/a"))This XPath grabs all the hyperlink text (not the links to archive.org versions) from the tables. Replace with your website as appropriate.

This call on seomoz.org returned around 150k URLs into an Excel document. As you might expect, on analysis there were a large number of chained redirects (some resulting in five redirects).
At this point we’d update the .htaccess to redirect each unique URL that is currently chained to the appropriate final destination.
There are performance questions to be weighed here, and you will need to get the relevant server administrators on your side (so perhaps don’t push the obsessive-timewasting-marginal-gains-angle). As SEOmoz has migrated, so we wouldn’t have to be too concerned with a performance hit from 150k mapped redirects.
Bookmarklet
If you’d like to quickly view the current domain in the web archive, use the following:
javascript:(function(){window.open('http://web.archive.org/web/*/'+location.host+'*')})();Create a new bookmark, paste the above code as the location.
Query The CDX API
Patrick Stox put out a post recently making use of a superior technique – we query the method the wayback machine uses.
You can see this in action here:
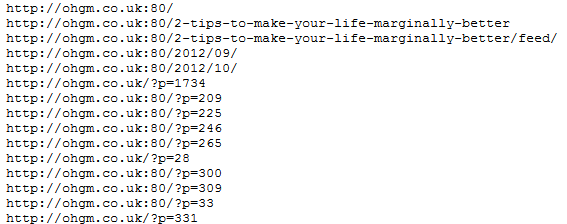
https://web.archive.org/cdx/search/cdx?url=ohgm.co.uk&matchType=domain&fl=original&collapse=urlkey&limit=100000
All you need to do to use this data is a quick find and replace to eliminate the port numbers and any other cruft. Once this is done, crawl to eliminate redirect chains and dead ends.
Taking This Further
If you want an even bigger dataset, you can batch download every page ever archived and extract the internal links. Deduplicating these will give you a very large historical dataset, perfect for crawling to eliminate redirect chains.
For this process I use the Wayback Machine Downloader to download a copy of all URLs matching a criteria (e.g. older than timestamp). From these I gather a list of unique internal links. However, this is a bit excessive for most, and the method above combined with orthodox methods will get you >80% of the way. Don’t become a domain necromancer. Turn back now.
Great post, Oliver!
Never crossed my mind to use the WayBackMachine like this…
This will be extremely helpful when doing Link Reclamation projects..
Solid post. Never knew about the unique pages feature on archive!
I’ve found using the All Pages report in Google Analytics to be very helpful for finding historical URLs.
I set the date range far into the past and then grab all the unique URLs and crawl them to see what the status codes are. From there, I can prioritise based on links/traffic, etc and recover the ones of value.
Thanks Ed – check out the method near the end of the Server Logs post. Very useful for finding old URLs analytics isn’t even installed on (if you can get the logs).
What did I read? Never knew this was possible with wayback machine. Glad that I found it now.
Hey, thanks. Keen to try this out, but stuck on first hurdle! Dropping this into the browser https://web.archive.org/web/*/ mysite.com e.g. nike.com* but getting ‘not found’ 404. What should I add to the browser? Thanks so much :)
Hey –
I’m seeing
https://web.archive.org/web/*/nike.com*working okThe CDX API is generally more useful though
https://web.archive.org/cdx/search/cdx?url=nike.com&matchType=domain&fl=original&collapse=urlkey&limit=100000