
This was one of the 5 topics I spoke about at ohgmcon (please see Robots.txt does not have to live there for another one). This idea was originally triggered by Vanessa Fox‘s excellent post on the keylime toolbox blog.
I’d previously believed that the crawl rate setting in Google Search Console couldn’t be used to increase the rate at which Google crawls a website, but only apply limits. This is usually expressed as:
“Only use this if you are experiencing difficulties from Googlebot crawling your site”
or repeatedly and emphatically in the tool itself:
“Don’t limit crawl rate unless Google is slowing down your server.”
Crawl Rate Defaults and SEO
If you scroll through your search console account, you’ll see that there are significant differences in the supplied crawl rates for each site.
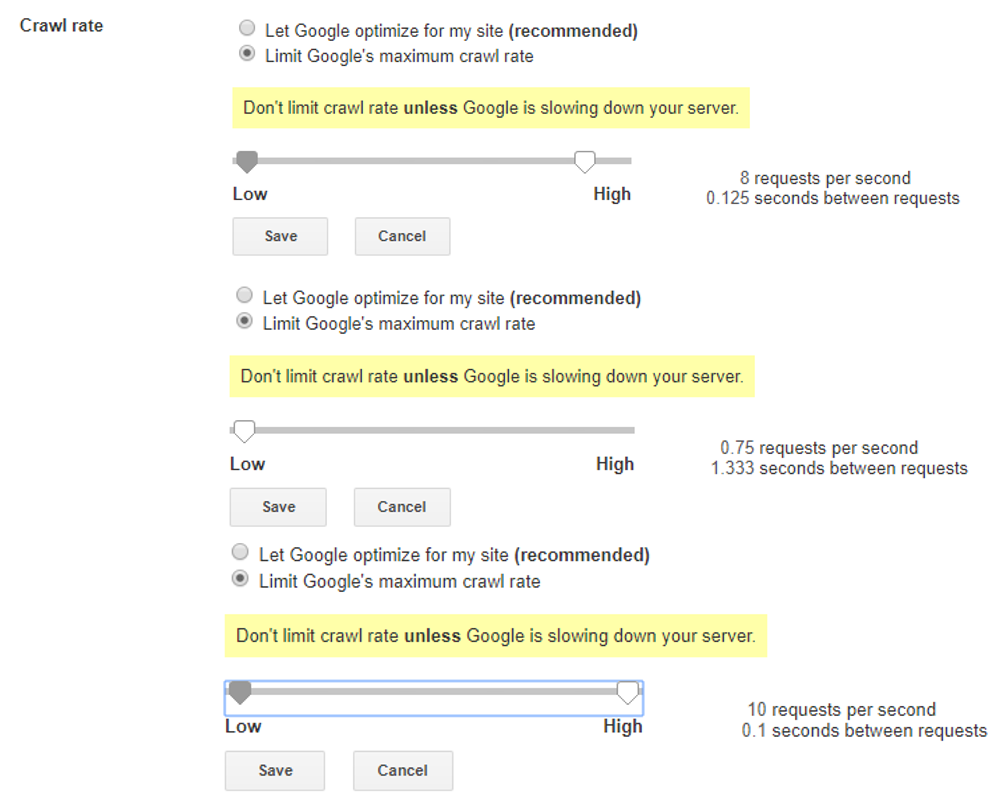
Here are the crawl rate defaults for an Ecommerce site (default, min, max):
And here are the crawl rate defaults for a High Quality SEO blog:
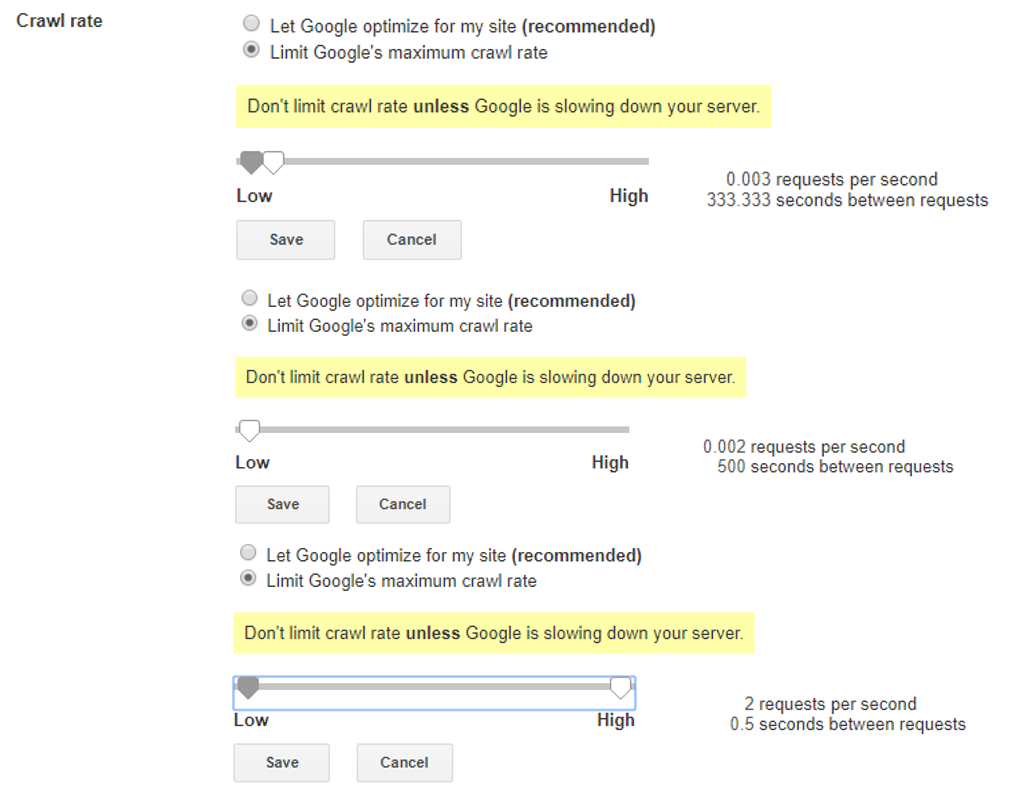
My understanding is that these aren’t real numbers but averages split into buckets. The buckets represent ranges. Actual crawling is way more dynamic and responsive than these buckets suggest, but they’re useful nonetheless. Sites in different buckets are crawled at significantly different frequencies.
The number shown on your bucket isn’t really indicative of your current crawl rate at all but an average of the bucket the site falls into, on average. An average of averages. My understanding is also wrong.
“Don’t limit crawl rate unless Google is slowing down your server.”
But in my mind, I’m offered a chance to go from the 0.003 requests per second bucket to the 2 requests per second bucket. I’m taking it.
Method
I slid that slider to High, and made a note in my analytics:
- Upped Crawl Rate Limit from 0.003 requests a second to 2 requests per second.
- Upped Crawl Rate Limit from 333.333 seconds between requests to 0.5 seconds between requests
No new content was published for the 90 day period the crawl rate change lasts. Which is good, because I didn’t have any ideas. Initial Results were immediate and interesting:
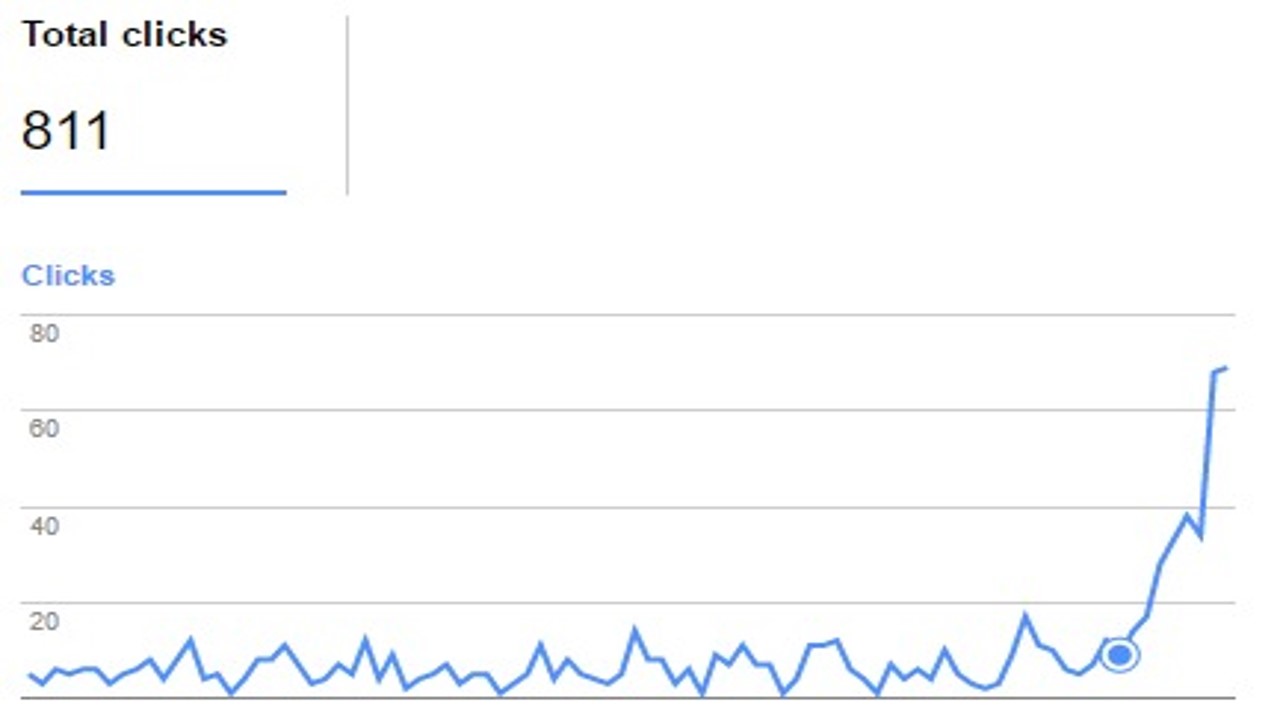
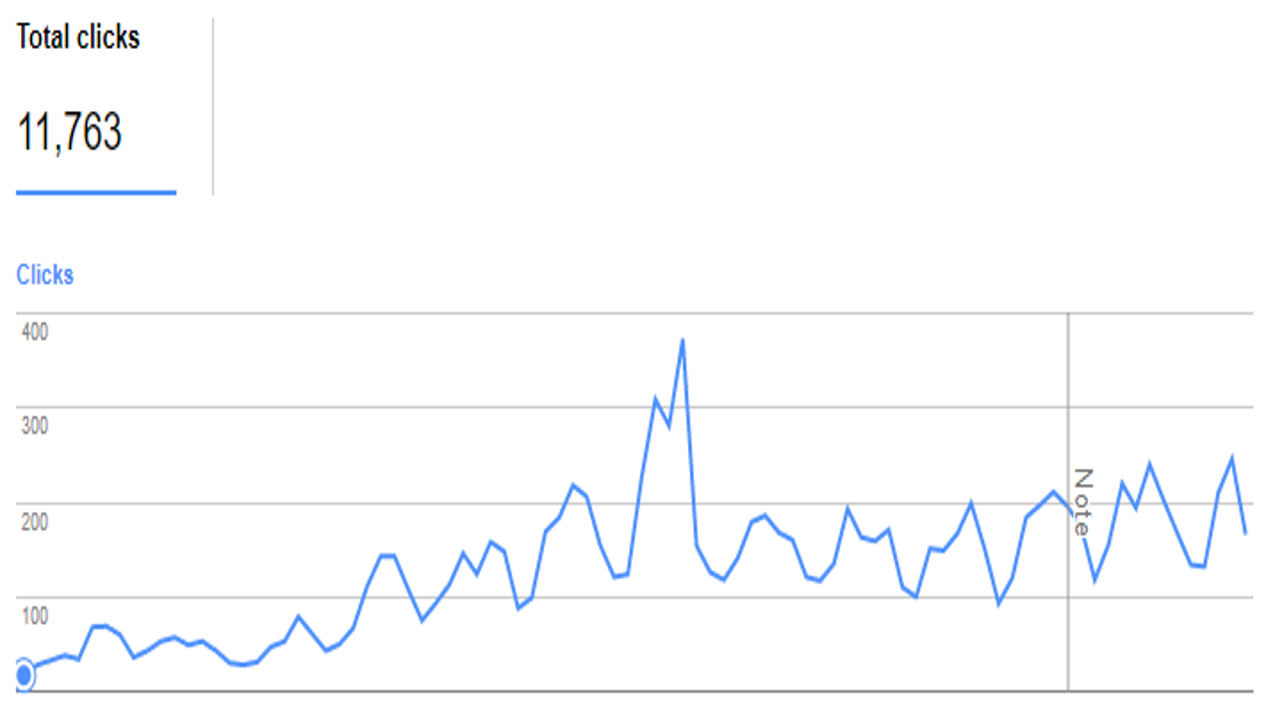
Actual Results
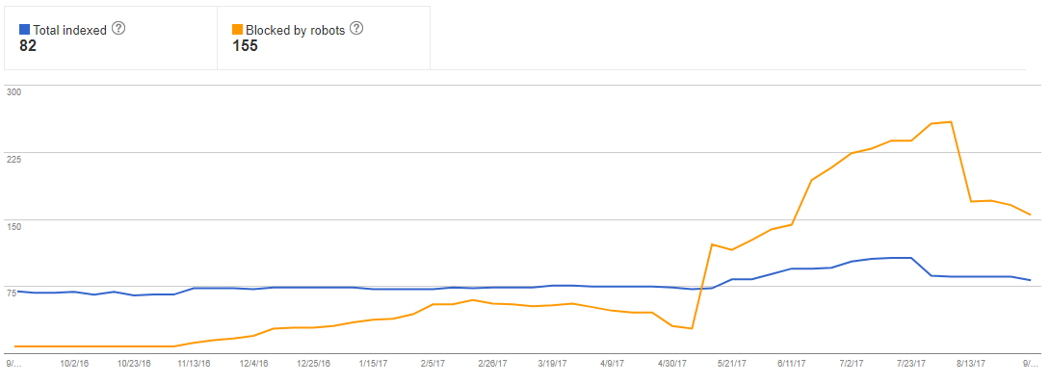
The site was only crawled marginally more frequently, but interestingly more unique URLs were requested (and as a result of the robots.txt setup, more blocked URLs were encountered):
Over the weeks, it received one weird tip increases in organic traffic from Google:
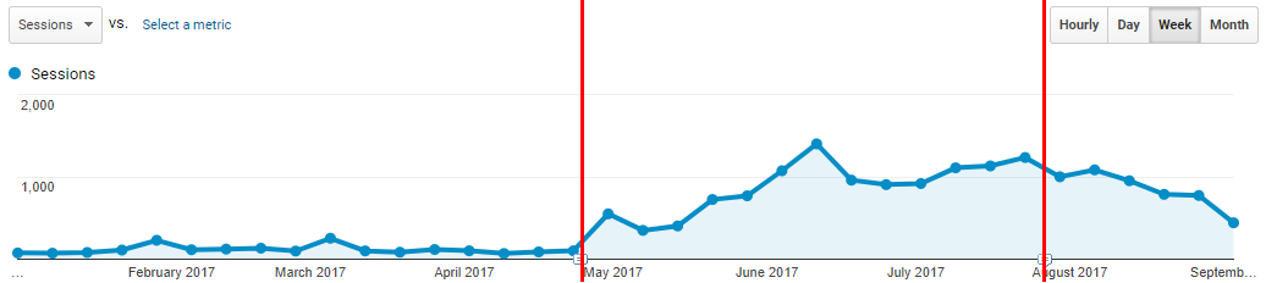
The red bars illustrate the start and the expiry of the directive. I could add some deceptive trendlines to this image. It’s very satisfying that the expiration of the directive appears to coincide with a decline in traffic.
Standard Disclaimer
Do not be lured in by my up-and-to-the-right graphs. As many of my posts now say:

I sent Chris Dyson this screenshot as a teaser a few days after my test began:
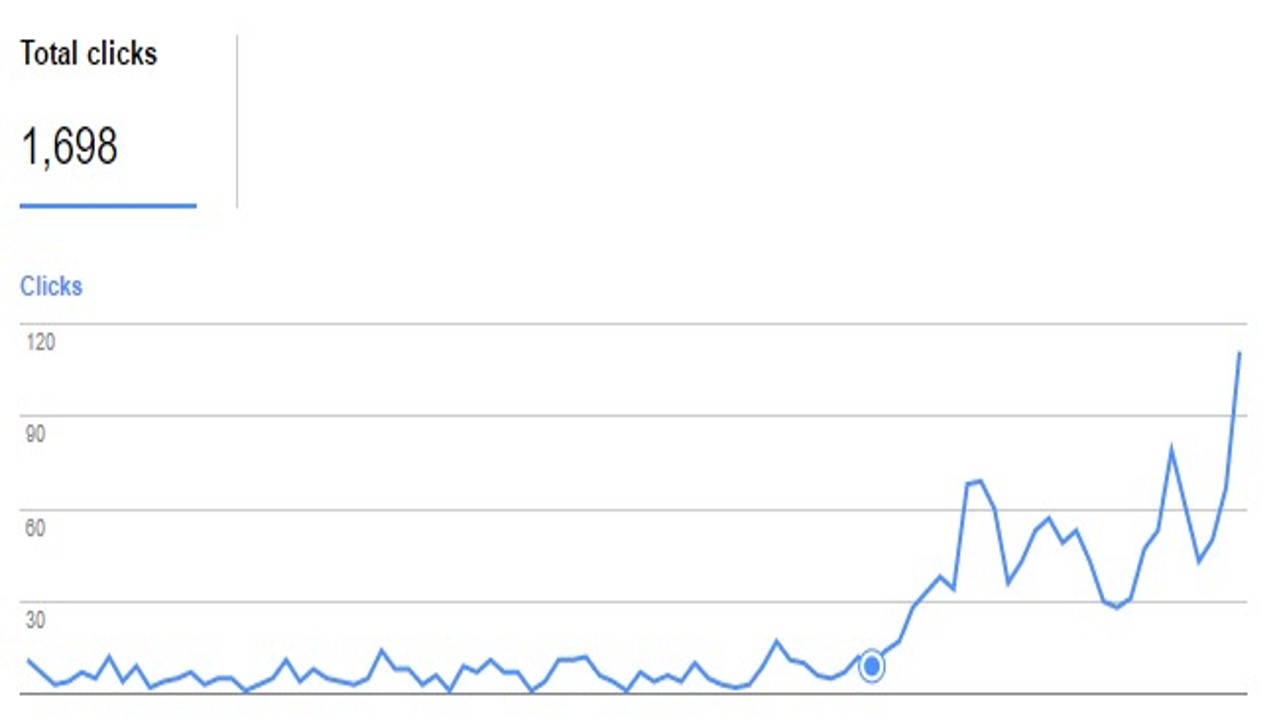
I thought that these results were interesting enough already for my presentation but that it’d be useful to see if it would work on a website which had traffic already. Chris works as an affiliate, so he implemented it on a few of his sites:
This is why I have these disclaimers.
The penalties were recovered almost immediately, as I understand.
Why do you think Chris’s no-doubt high-quality content would get penalised the day the directives expired? We thought the most likely explanation was that the expiration triggered a manual review flag, probably because it’s a rarely used feature only used by sites which are actually struggling. He just happened to put his sites in the firing line. This website got a pass, two of his did not.
Like my undeserved new levels of traffic, the penalty might of course just be a coincidence. Gary Illyes said:
██ █████ ████ ██ ██ █████. ██ ████ ██ ███████ ██ ██ ████ ██ ████ ██ █ ██████ ██ ██████.
Interesting! Again, don’t do this on a website you care about. I think it’s safe to say that implementing this on your own site won’t give you the same results.
If you liked this post I think you’ll find this other post much more interesting.
Gary Illyes said… What?
He said ██ █████ ████ ██ ██ █████. ██ ████ ██ ███████ ██ ██ ████ ██ ████ ██ █ ██████ ██ ██████.
it’s intrigue
Take a guess which saddo with too much time on hands did back in the same year that you published this post?
I applied for the trademark for ‘ Crawl rate’ – https://trademarks.ipo.gov.uk/ipo-tmcase/page/Results/1/UK00003217977