
My talk at ohgmcon was split into five topics – this blog post is about one of these, condensing two frantic minutes in a dark basement into something for a less captive audience. Enjoy.
This test was inspired by Alec Bertram‘s response to my post on Shopify not allowing robots.txt modification (update 06.2021, now they do) I know Alec had run an initial test regarding this and had encountered some interesting initial results. I managed to replicate this and push a little further.
Fair Warning: my robots.txt file was comical even before this post:
Since the robots.txt has attracted a few external links as a result of being so counter-intuitive, I have been using a HTTP canonical to to refer to robots.html in order to give this external PageRank somewhere to go. It works.
Now, because of the format of my robots.txt, I have to manually set allow rules for any post I’d like crawled. Right now, I’ll need to manually allow crawlers access to the current post, and the recap post and some later pagination as the number of posts on the blog increases.
Migrating Robots.txt
I started off by uploading a new file /this-is-wrong.txt to the server, and 301 redirecting /robots.txt to this location. /this-is-wrong.txt contained the contents of robots.txt, and additional rules to allow Google to crawl the location. These do not appear in the original /robots.txt. The new content appeared in search console’s robots.txt testing tool:
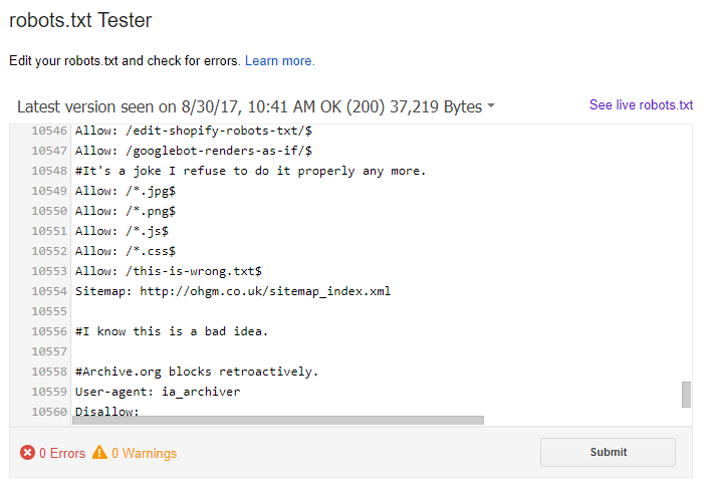
The new rules were also being respected by fetch & render, too. This at least indicates that it’s being picked up by search console (possibly in error).
When I redirected robots.txt to the new location, you might think it should have failed to function, because no allow rule was set in the cached robots.txt being used. Regarding this, Google’s documentation on robots.txt says:
Handling of robots.txt redirects to disallowed URLs is undefined and discouraged.
It also goes on to say:
Handling of logical redirects for the robots.txt file based on HTML content that returns 2xx (frames, JavaScript, or meta refresh-type redirects) is undefined and discouraged.
One for another post. Regardless, a redirected robots.txt will override the directives of the cached robots.txt Google typically uses. Nice to know.
Cross Domain Robots.txt
Our aim is to have custom robots.txt rules on a CMS which forbids them.
So a robots.txt on your own site in a different location seems to function well enough. This could be used to bypass some CMS restrictions. The brick wall seems to be that some platforms (e.g. Shopify) don’t actually allow you to upload static files to your own domain. Instead they must be uploaded to the CDN subdomain cdn.shopify.com.
So our custom robots.txt will have to be cross domain, which is where we should give up. Robots.txt files are only valid for the domain they’re hosted on. But since cross-domain sitemaps and other directives are respected, why not 3rd party robots.txt files? Shockingly, there doesn’t appear to be anything in the documentation regarding this.
I uploaded a new robots.txt file to a carefully-chosen 3rd party pastebin and updated the redirect to reference the URL for the raw file:
This new file is not on a /robots.txt URL. I made sure this pastebin wasn’t blocking user uploads in its own robots.txt, or returning any unusual HTTP header directives on user uploads. After submission, the robots.txt testing tool is populated with the contents of the pastebin file:
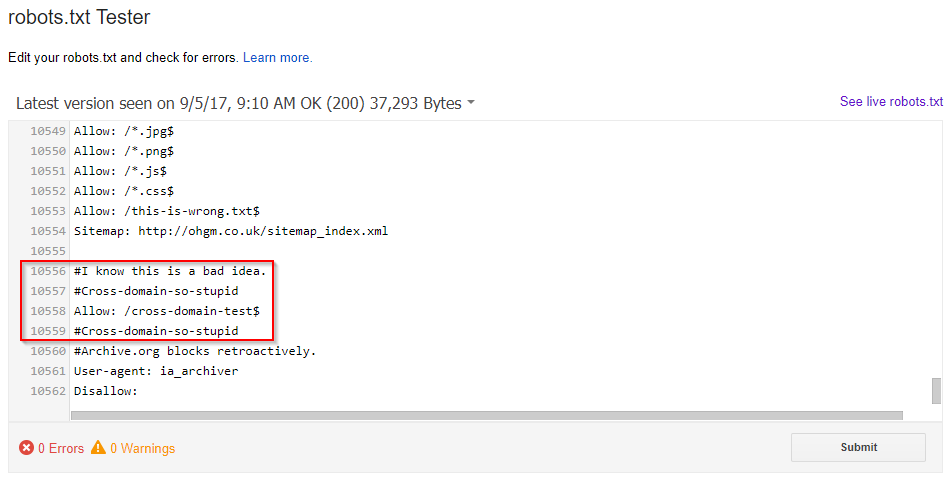
Testing a few fetch and render submissions, everything works as intended:
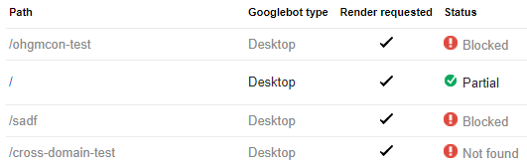
- ‘/ohgmcon-test’ is blocked by the blanket disallow. If the URL gets indexed (sitewide link to encourage), the content won’t be, and it’ll be indexed with a ‘blocked in robots’ warning.
- The homepage is crawlable as a result of the respected allow rule.
- ‘/sadf’ is blocked, because there is no allow rule.
- ‘/cross-domain-test’ is crawlable, but an error, because there’s nothing there.
Incidentally, Bing is displaying the ‘blocked in robots.txt’ warnings as hoped:
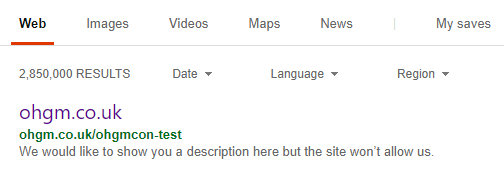
It’s a little harder to force Google to show this for a small site (“index something I don’t want you crawling, please”). Update – it works:

In the case of redirection, robots.txt directives are honoured for the domain that sent them, and not the domain that they reside on.
Since the canonical to robots.html was dropped as a result of the 301 redirect being implemented, it became possible for Google to index both page formats:

Interestingly, the URL appearing for this cache (ohgm.co.uk/robots.txt) is the 301 redirect. The text appearing in the cache is the unique text only found on the pastebin:
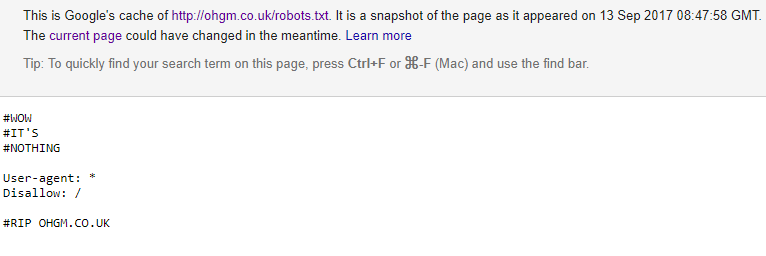
Crucially it shows rules which only ever existed on the pastebin, attributed to the ohgm.co.uk/robots.txt URL. To me this is a pretty strong indicator that it’s not merely a search console quirk. The cache date presented here has updated several times (even though we’re not supposed to care about the cache date). More importantly, all the directives I currently have in place (Disallow, Allow, and Noindex) are being respected.
If this holds then:
You can implement a custom robots.txt for any site on any CMS you can implement redirects on.
In the ideal scenario, the following is true:
- You can redirect arbitrary URLs. You might not have the ability to do this through a CMS interface, or at the server level, but it should be possible to implement this single redirect through the DNS or at the CDN level.
- You can upload .txt files to a domain/location you actually control.
That’s worth having in the toolkit – even if you file it under “things I will never advise a client to do“. Please don’t take this idea and 10X Soloprenuer an “SEO-friendly robots.txt platform”.
Risk Tolerance
I’m risking very little by running this on ohgm.co.uk – I’m only giving up the value of the external links pointing at my robots.txt for the purposes of an experiment. If my robots.txt stops functioning I’m not going to have layoffs. I am advising you not to do this:

Think about other search engines, or what you’ll do when your client/boss is asking where all the traffic went. If you have a higher risk tolerance, go for it.
DM me if you spot any of these in the wild. The unfortunate thing is that I’m going to have to modify the current running test in order to have this page crawlable. If this is of concern to you, replicate the test. I imagine this will stop working abruptly.
Migration Gotcha
Update: I’ve thought of something I think you might one day encounter which isn’t a pure marginal edge case. I’ve seen ‘remember to redirect robots.txt‘ raised as a migration gotcha before. I think it can cause another. Migrations are the most common cause of robots.txt being redirected, so this is worth considering.
Imagine you’re doing a domain migration, and the URL structure is changing. You’re mapping old categories to closest new equivalents. Understandably you redirect robots.txt:
- example.old/pink-dresses –301–> example.new/dresses
- example.old/robots.txt –301–> example.new/robots.txt
On the old site, /pink-dresses was a meaningful category. On the new site, /pink-dresses is a horrific facet, and it’s blocked in robots.txt.
If Googlebot is only respecting example.new/robots.txt, then the redirects from the old site to the new site will not be followed by Googlebot.
URLs on the OLD site which the NEW robots.txt is blocking will not be crawled, even if they are being redirected to the new structure. Value will not pass. This could be bad news.
There are two reasonable responses to this.
- Don’t redirect your robots.txt, or redirect it to a different URL so that ‘there is no robots.txt‘ meaning there are no restrictions on crawl of the redirects from example.old. Problem solved.
- Be quite careful.
The easiest way I can think to check for this is to take your redirect mapping list for the origin and replace the old domain with the destination domain. example.old/pink-dresses would be replaced with example.new/pink-dresses. Crawling this list will show you which origin URLs will be blocked by the new robots.txt.
I’ve still not yet heard from anyone trying this out. Lots of you have been adjusting the crawl rate sliders (enjoy your penalties, I guess), but no-one seems reckless enough to implement it. For shame.
Very interesting to learn that Google follows redirects to /robots.txt (even external). I’d imagine most ‘smarter’ robots follow some redirects. Like checking for /robots.txt on HTTP variant and getting redirected tot HTTPS.
The official specification doesn’t say anything about redirects. Only that an empty (e.g. HTTP 404) /robots.txt should be treated as “all robots welcome”. Most robots probably check for a HTTP 200 header and if it’s not there assume it’s welcome.
Thanks for the comment Martijn – weirdly I’m seeing the same behaviour in Bing Webmaster Tools for the ‘fetch as Bing’ feature.
/ohgmcon-test is reported as blocked in robots.txt , as there’s no allow rule.
/cross-domain-test is accessible for Bing (but 404s) – as there’s only an allow rule in the pastebin this seems significant.
/ is accessible.
Hi Oliver, have you found any examples in the wild by now? Thanks, best, Andy