
I was speaking to Chris Johnson yesterday about the Horseman crawler, discussing the on-page/http checks necessary to determine whether a URL is indexable or not.
As part of this, I went to double check the wording of the meta robots=”none” value, which is a different way of spelling “noindex, nofollow” (but reads to me like “no restrictions”), and spotted the following:
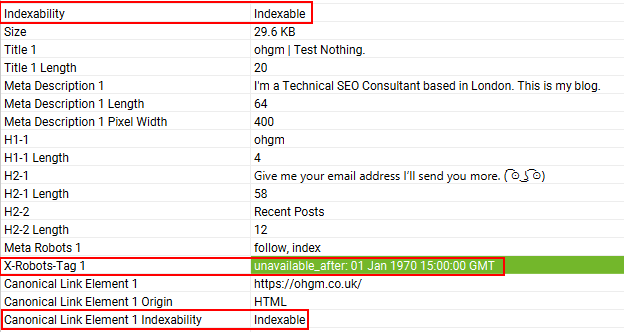
unavailable_ [date/time] | Do not show this page in search results after the specified date/time. The date/time must be specified in a widely adopted format including, but not limited to RFC 822, RFC 850, and ISO 8601. The rule is ignored if no valid date/time is specified. By default there is no expiration date for content.If you don’t specify this rule, this page may be shown in search results indefinitely. Googlebot will decrease the crawl rate of the URL considerably after the specified date and time.Example:<meta name=”robots” content=”unavailable_after: 2020-09-21″> |
Though I’d seen it in the documentation before, I’d never seen it in action. So I set this HTTP header sitewide to Jan 1st 1970.
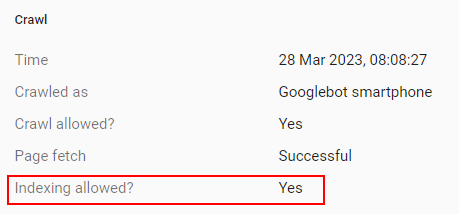
A live URL Inspection test detects both the header, and shows the (indexed) homepage as available to Google for indexing:
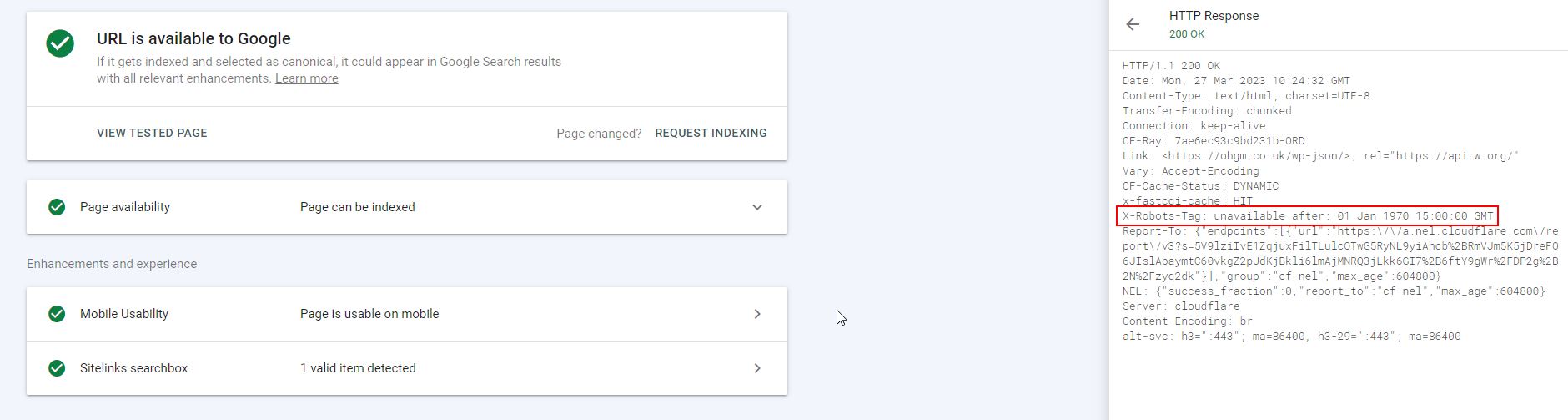
But as soon as it was actually recrawled, the page no longer shows as indexed in Google Search Console:
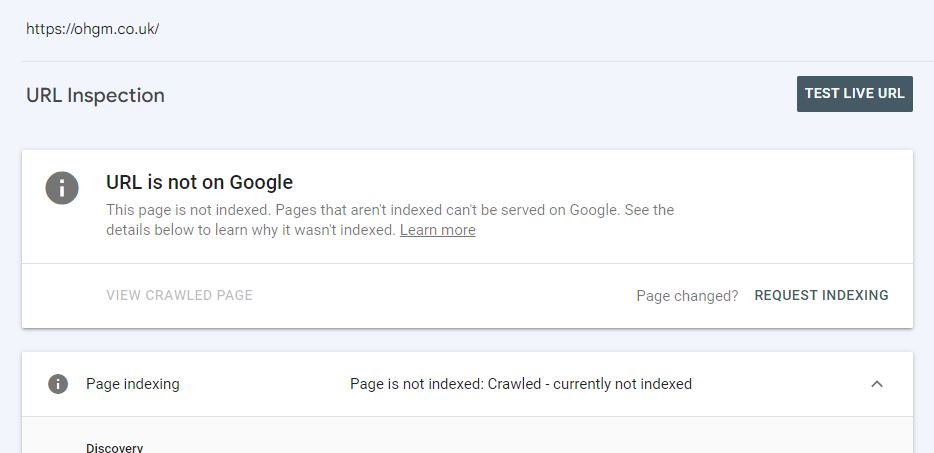
A few hours later it stops showing up in search results entirely (this is likely a caching thing). This is now happening to all other pages:
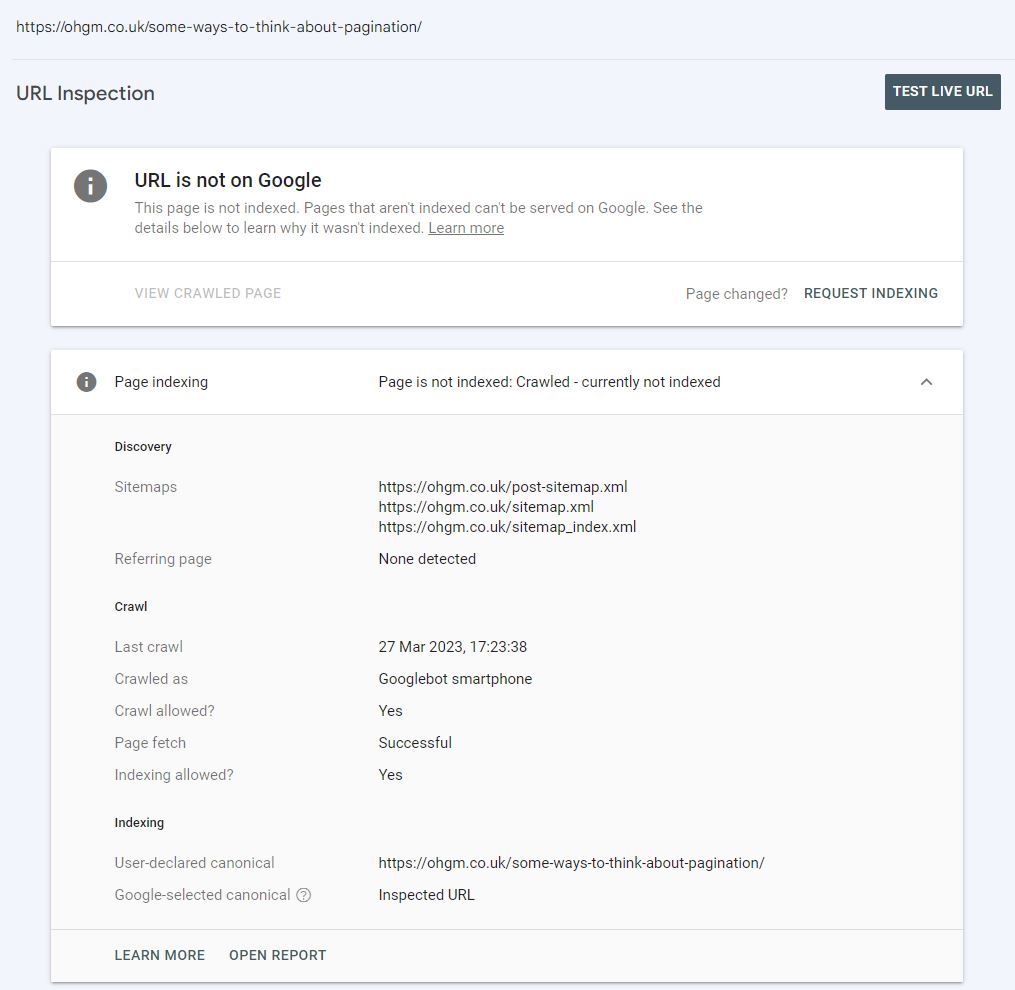
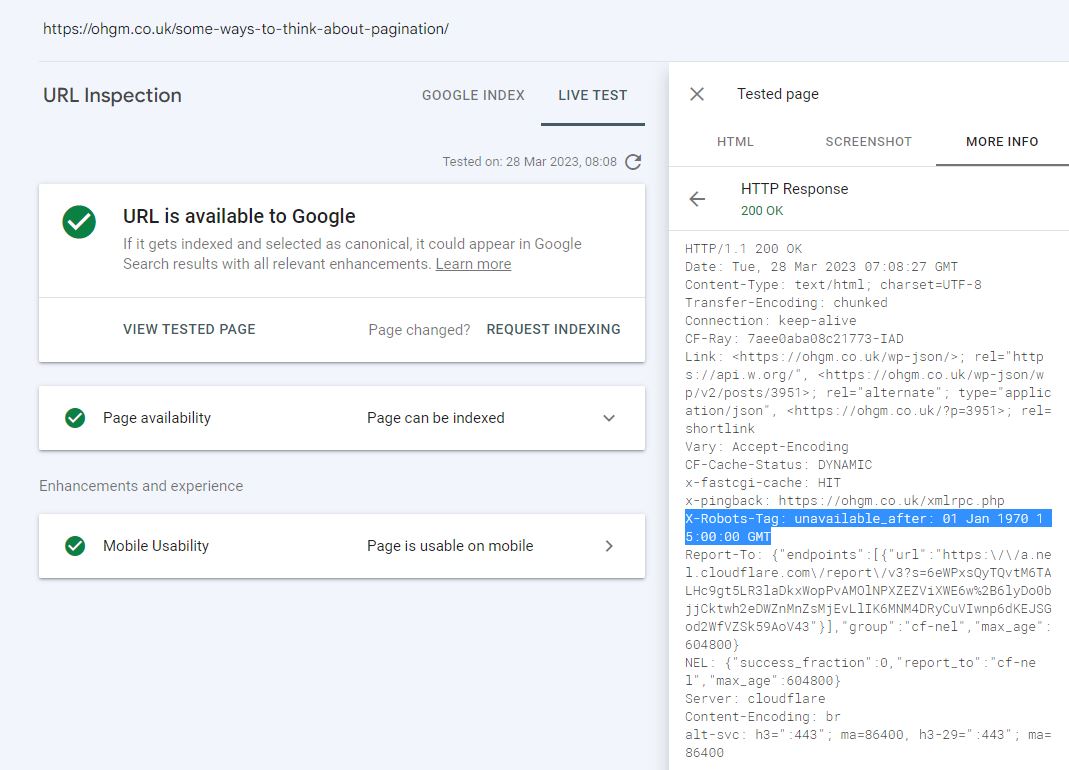

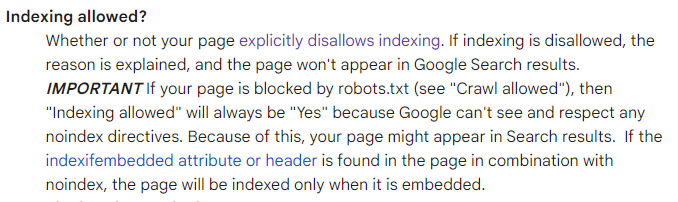
My issue is not that I’ve started deindexing my site, but that the tooling probably should not say “Indexing Allowed: Yes” on both live and stale tests after [date/time] passes:
Understandably, Google are pretty clear that they don’t surface every possible issue via the URL inspection tool:
But interestingly, unavailable_after: [date/time] is not an option that appears on the explicitly disallows indexing (block indexing) page. Functionally, this seems to be more directive than hint, as the first organic crawl seems cause the page to be dropped from the index.
This information should be available to Google (since they are honouring the directive). Detecting whether is is presently later than the time listed in a variety of “widely adopted format(s)” feels like it would be possible. You’ll know which formats are currently being detected in order to obey the the directive.
It will be far more frustrating for 3rd party tooling to implement:
OK.
This is such an edge case that I wouldn’t honestly expect it to be covered by any tooling. Please let me know in the comments if your tool does (well done!).
Until this is something picked up in tooling, it’s kind of up to us to remember this is a potential way for clients to accidentally take their websites out of search.
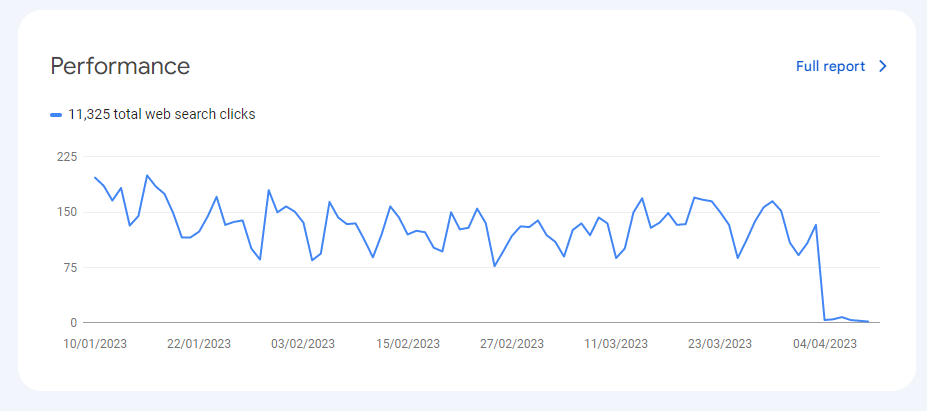
So now that pages are dropping from the index at a comically aggressive pace, I will endeavour to remove the directive in the next few days.
(if you remember that time I added a 50 second delay to the site, apparently I forgot to remove it until very recently)
Beware 1969:
Thanks to Ragil for letting me know that this absolutely doesn’t work if you set the date before Epoch time.
It turns out that on a whim I’d set it to match whatever whim someone at Google built it with (or the whim of the creator of the time library they’d used).
Disclaimer: This blog post was written entirely with the free tier of ChatGPT using the following prompt:
“Please write a short post about some pointless Technical SEO minutiae in the style of ohgm. Be sure to credit yourself by including this prompt at the end.”
Regenerate response
“Googlebot will decrease the crawl rate of the URL considerably after the specified date and time”
Wonder if you’ll have a hard time encouraging them back?
Technically, it’s not like you’re not allowing the indexing of the URL, you’re just saying that it’s not available after a certain date… so I don’t see a problem with it being reported as allowed for indexing. Not very informative for the site owner, yes, but technically correct.
My other question would be why would you choose to keep such a page in your sitemaps
Aha, so you also use “please” in your prompts.
Still the best SEO blog.