
One of the lovely parts of Google Search Console is the Settings > Crawl Stats report suite:
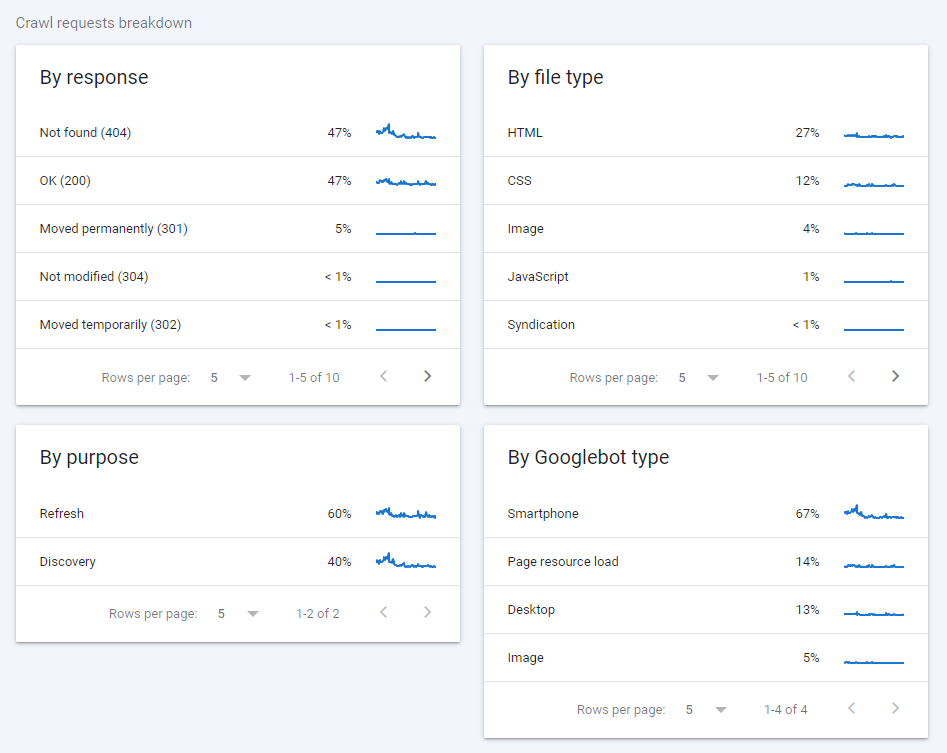
And something I only noticed today is the unexpectedly friendly URL structure:
/search-console/settings/crawl-stats/drilldown?resource_id=sc-domain%3Aohgm.co.uk&response=1If you haven’t had enough coffee today, this probably means the following will do something:
/search-console/settings/crawl-stats/drilldown?resource_id=sc-domain%3Aohgm.co.uk&response=2and it does.
(I don’t usually see the parameters at the end of the URL because I have too many pinned extensions in Chrome).
This post is just me finding something interesting, rather than uncovering this THING they don’t want you to know.
And the documentation is really good here: https://support.google.com/webmasters/answer/9679690?hl=en
So it’s not like I’m discovering much here. Enjoy.
&response=
I am just going to run through and list the responses for each parameter.
- OK (200)
- Not found (404)
- Unauthorised (401/407)
- Other client error (4xx)
- DNS error
- Fetch Error
- Blocked by robots.txt
- This returns a 400 for some reason.
- Server error (5xx)
- DNS unresponsive
- robots.txt not available
- Page could not be reached
- Page timeout
- This returns a 400 for some reason.
- Redirect error
- Other fetch error
- Moved permanently (301)
- Moved temporarily (302)
- Moved (other)
- Not modified (304)
&file_type=
- HTML
- Image
- Video
- JavaScript
- CSS
- Other file type
- This returns a 400 for some reason.
- Unknown (failed requests)
- Other XML
- JSON
- Syndication
- Audio
- Geographic data
&purpose=
- Discovery
- Refresh
- Other fetch purpose
( ͡° ͜ʖ ͡°)
&googlebot_type=
- Smartphone
- Desktop
- Image
- Video
- Page resource load
- Other agent type
- Adsbot
- Storebot
- AMP
Anything interesting?
Yes, please have a look yourself. I will dig in more once I have the will.
- Why are a few of these options returning a 400?
- I’ve never seen many of these in the wild – are they all functional or placeholders for planned/deprecated/currently broken reports?
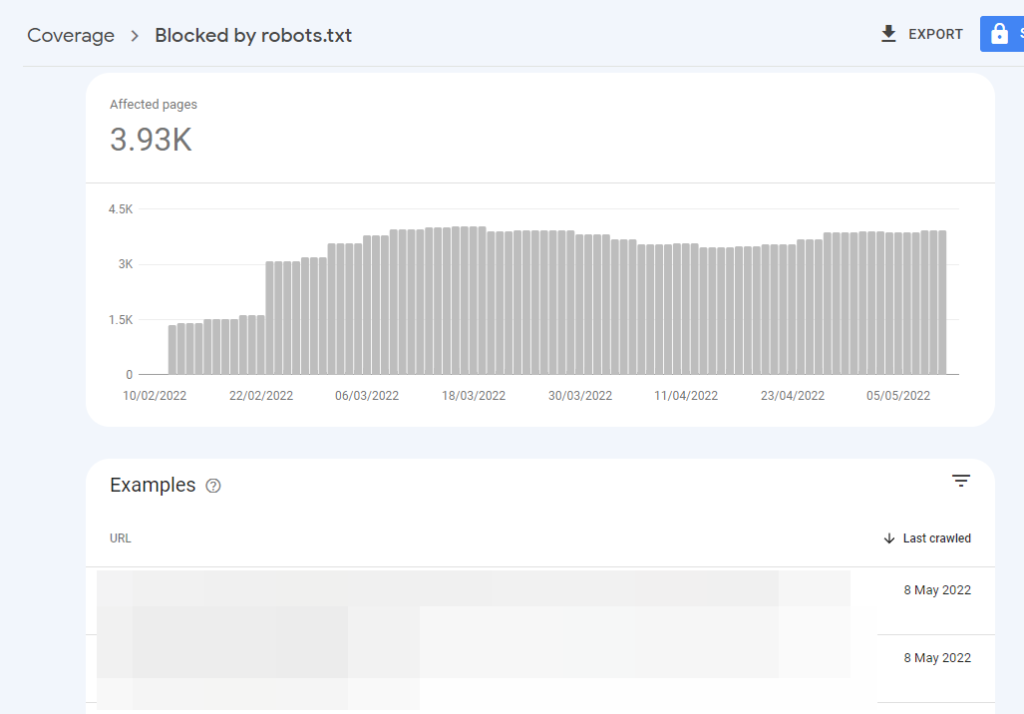
For example, I don’t think I’ve ever seen Blocked by robots.txt (&response=7) show up in this report before. It does show up in Coverage with ‘last crawl’ dates (I had a look at this back in 2018 to see whether blocked crawl ‘attempts’ were recorded):
But this particular crawl stats report doesn’t seem to be populated for any sites I currently have access to:
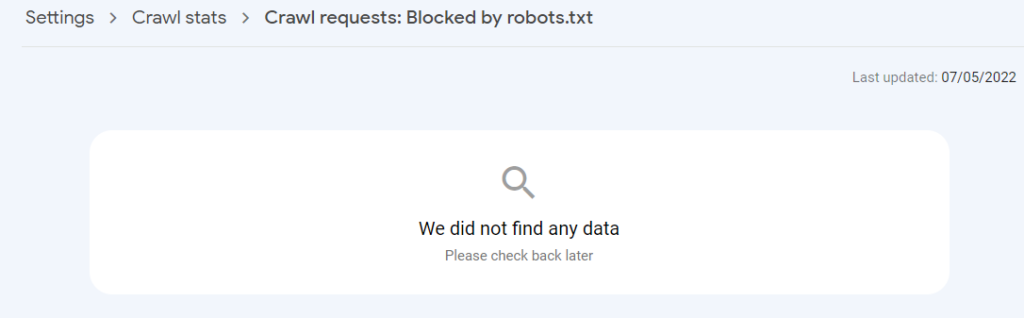
And you would expect it to be if we’re getting the coverage report showing recently ‘crawled’ URLs.
The documentation indicates it probably is intended to function:
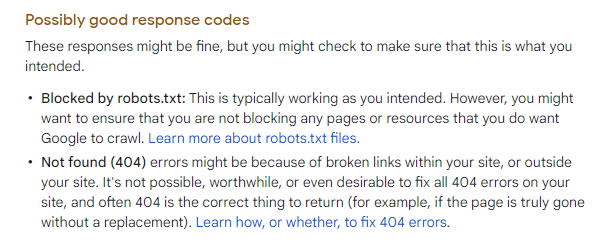
Maybe it works for you, let me know! It might be temporarily broken (and I’ve previously been inattentive).
I hope some tool providers can use these URL formats for more efficient scraping.
This post could be a tweet thread, but if I did that, I’d never find it ever again.
no, the ones that don’t work for you also don’t work for me. I tried 2 domain level properties and two URL prefix.
Thank you for the parameter value list / overview.