
Last week I read Emma Barnes‘ post on the Branded3 blog. It got me thinking. Essentially pdf’s rank fine but are a pain to track properly in Analytics, so translating them into a more friendly format like html is preferable.
Before you start reading the post please note: This is a curiosity (or dead end). This is not a viable ranking strategy. This is a waste of your time.
I initially thought that translating pdf to files to complete webpages probably wasn’t worth the time expenditure for developers in most cases. The resource already ranks, right?
Well, if it’s not ranking in 1st we’re probably tempted to fiddle with it. And we do want decent tracking information if it’s for a term with search volume. And we have a lot more options for fiddling with it if we convert the file to HTML.
This would work something like:
- Batch convert pdfs to html.
- Insert desired tracking codes (during conversion should be easy enough).
- Insert all those desired SEO tags and markup, Schema etc.
- Redirect original pdf to new html URL.
- Upload original pdf to new URL, blocked in robots.txt.
Just like PSD-TO-HTML services, there are plenty of pdf-to-html conversion websites available. As usual, I’m more interested in tools we can use locally (since some sites have hundreds of pdf’s they’d rather batch convert).
pdf2htmlEX
Enter pdf2htmlEX, a free cross-platform command-line utility that performs near perfect conversion. I’ve only played with the default settings, but typesetting, images, fonts (nearly all fonts, anyway), look great:

You’re not going to be getting responsive output. You’re going to be dumping out something that looks identical to the input.
So the code looks like a mess, but it’s fully functional (and very impressive). Everything is reduced to a single (large) html file. Images are encoded inline as a background layer:
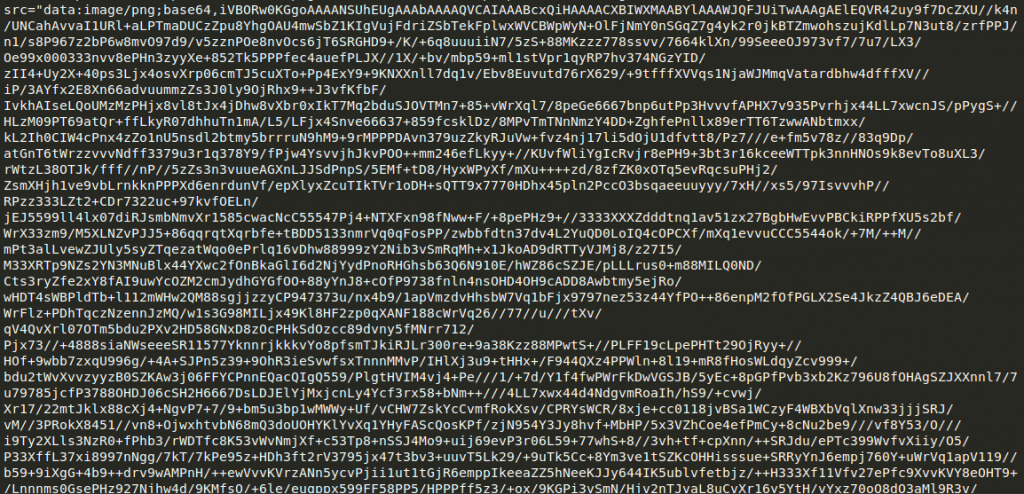 Typesetting is performed with a plethora of span tags and CSS rules:
Typesetting is performed with a plethora of span tags and CSS rules:

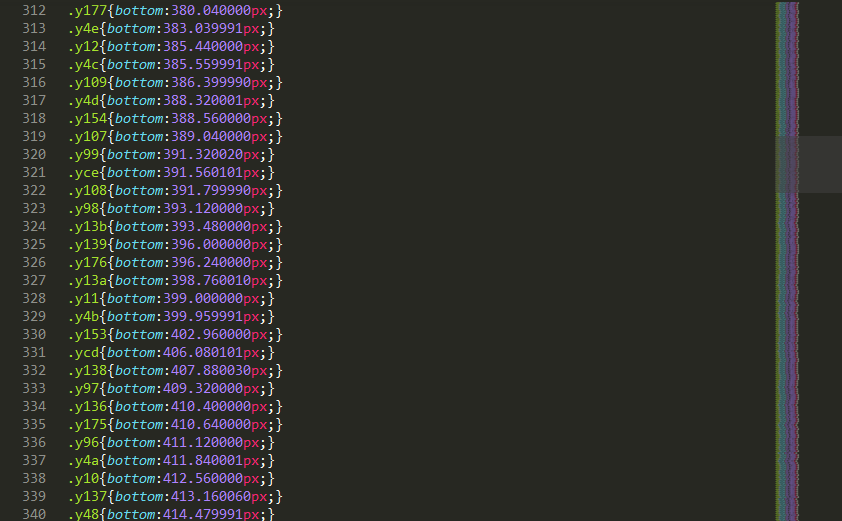
You can’t knock the accuracy, though.
So the generated code isn’t going to win any style awards, and is certainly going to be a nightmare for Googlebot to parse. So how does Google handle this generated code?
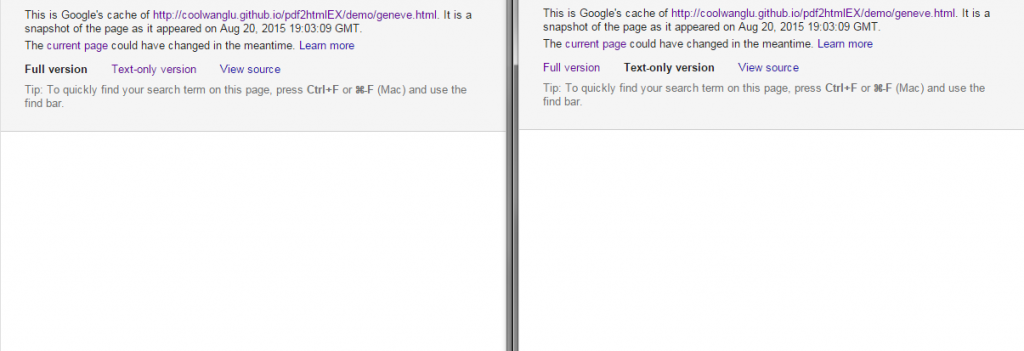
It’s caching it, but it doesn’t understand how to render it. Well – this online version is using the lazy loading preset, which is unfair on Google, so I’ve uploaded it again here.
Fetch and Render
Even if Google could perfectly parse this information, it still might not want to have another version of the document online. As it’s full of unusual characters, it’s already at a disadvantage. For this reason I’ve put up another test converted pdf here. It contains more typical sentences, hopefully enough to get indexed without too much trouble. We’ll see – I believe it’s a challenge, but fetch and render handles both without any trouble:

 Do you think we can trust fetch and render here?
Do you think we can trust fetch and render here?
I’ll be checking whether the test URLs are cached and indexed in a few days. Once they are, I think we’ll see something interesting about fetch and render.
Update: 26.10.15 – They’ve Indexed and Cached the test URL
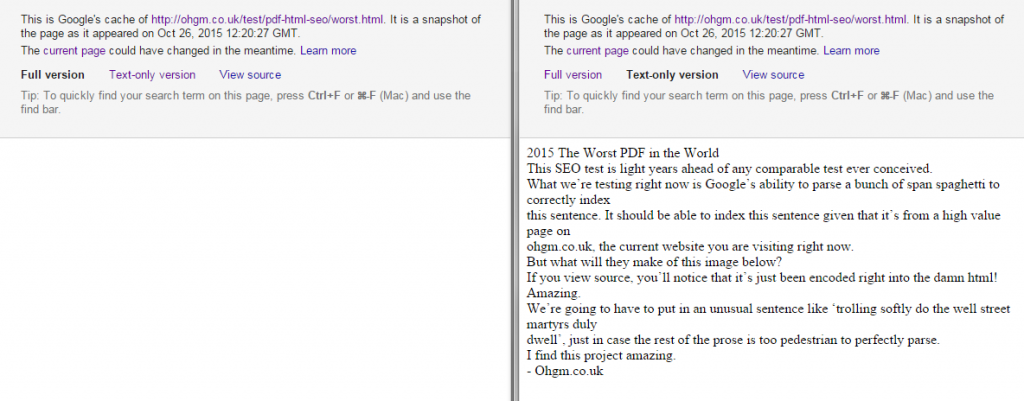
They aren’t rendering it in the cache like they are in ‘fetch and render’.
Update: 28.10.15 – They’ve not indexed the duplicate test URL
They’ve also added a full stop:

Chris Dyson raised an interesting point – How do text only browsers view this?
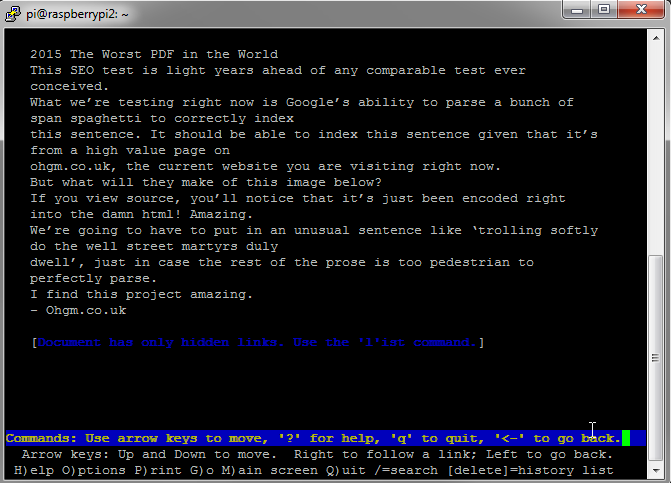 You’ll notice that lynx (the text-based browser) has the same formatting issues as Google’s cached text-only version of the page.
You’ll notice that lynx (the text-based browser) has the same formatting issues as Google’s cached text-only version of the page.
Initial Theory:
Fetch and Render is a separate ‘take your time, full resources and capabilities’ version of Googlebot. Fetch and Render is the Googlebot that makes new year’s resolutions. It is what Googlebot can do if it spends the time necessary to parse your content.
There are very few Fetch & Render requests for Google to deal with, when compared to crawling and indexing the internet. Google don’t use the full Fetch and Render capabilities in practice. This would be very expensive at their scale, so they don’t do it. The ordinary Googlebot is the one that gives us the cache. It’s the same deal with AngularJS (test).
The translated pdf’s code is obscure enough that it can’t be parsed with the standard resources allocated to it, but not so obscure it can’t be parsed in Fetch & Render (basically Chromium). Not as well as a regular pdf, anyway.
In short: care about the cache.
If the machine-generated page ranks (and it were somehow the same size), is there any advantage to hand-converting over machine converting?
Hey dude,
Thanks for testing this for me! This is ace.
Think there’s a lot of potential benefit for translating certain content (especially if you want to measure it), and if there was a really good way to automate it, why not.
In the end, it’s a real cost & risk vs reward.
What a lad.
Great post. Honestly, it’s refreshing to read the stuff you are doing.
Tom
How did you get pdf2htmlEX to work in batches? I have a few PDF files in a folder, but I can’t get it to work…
Study Bash.