

This blog post is some thoughts on PageRank sculpting adapted from my Brighton SEO presentation. The previous entry Laundering Irrelevance spoke about how you can create duplicate content to create similarity between topically distinct pagetypes.
It’s Not All About PageRank is of course a title fake-out. This post is mostly about an abstract and incorrect but useful approach to something which isn’t actually PageRank. The goal of this series is to make me write a completely new presentation by the time BrightonSEO actually does roll around.
PageRank is still very, very important for ranking but difficult to understand intuitively. Frankly, I do not understand it nearly well enough to talk about it as confidently as I do. Most SEOs (to reiterate, me) do not.
PageRank Sculpting aims to maximise the PageRank of URLs we care about by minimising the PageRank passed to URLs (internal or external) we do not. Although my approach is strictly speaking wrong, the results are impressive enough for me to continue to exist.
To contextualise this, let’s talk about PageRank Sculpting in olden times, which made use of the “nofollow” link attribute:
So what happens when you have a page with “ten PageRank points” and ten outgoing links, and five of those links are nofollowed? [...] Originally, the five links without nofollow would have flowed two points of PageRank each (in essence, the nofollowed links didn’t count toward the denominator when dividing PageRank by the outdegree of the page). More than a year ago, Google changed how the PageRank flows so that the five links without nofollow would flow one point of PageRank each. - "PageRank sculpting" by Matt Cutts, 2009
By cutting off the flow of PageRank to URLs we did not care about, SEOs were able to increase the ranking potential of the remainder.
With some thought, we can continue to do this.
Prerequisite Reading
This post is abstract and the concept simple, but it leans heavily on some prerequisite knowledge. I know you aren’t going to read these now, but consider them “further reading you should have already read”
- Proposing Better Ways to Think about Internal Linking
- Internal Link Optimization With TIPR
- Yes, I’m Linking to Those PageRank CheiRank Pagination Visualisations Again
These posts each link to many other great posts. May they all benefit from the PageRank.
Idiot’s Approach to PageRank Sculpting
My Idiot’s Approach to PageRank Sculpting is easy to grasp:
- Remove unnecessary links.
- Link to the URLs you care about from other URLs with lots of PageRank.
- Link more prominently to URLs you care about vs URLs you do not.
We’re just going to concentrate on the first of these.

Removing Unnecessary Links
Taking Kevin Indig’s approach to internal linking (“take from the rich, give to the poor”) , and wilfully misinterpreting it:
"Shh, shh. No more tears, only dreams. Peace now."
We are essentially starving these pages of PageRank, and in some cases intentionally creating orphans.
Please embrace the following idea:
A link that doesn’t appear to exist to Googlebot doesn’t get assigned PageRank.
Which means if you can find ways to make this the case for links to URLs we do not care very much about, we can improve the ranking potential of the remainder.
One classic way to stop links from appearing to exist is by deleting them. This should be done wherever this is not a terrible idea. We’re not going to talk about this.
Generally, the next best way for links to “not exist” is by looking at things from Google’s perspective and catering to it. This is often confused with Cloaking :
"Cloaking refers to the practice of presenting different content or URLs to human users and search engines." - Google, being crystal clear.
And you can cloak to do this! But it’s possible to make things not work for search engines whilst working for human users, without presenting different content.
Using Unrecognisable Link Formats
The first method is to use intentionally wrong link formats. For a typical user, anything that takes them somewhere else with a click event is a link or a button. For search engines, this is not at all the case, and this gap is something we can work with.
If you’ve read presentations and blog posts on JavaScript SEO, you’ll know that some link formats will not work for search (because strictly speaking, they aren’t actually links by any specification):

Thankfully browsers correct for this. But consider the idea from the other direction. You want to know the most broken link formats for that still work for users, but are completely useless for search engines when assessing what is and is not a link. If you’ve done JavaScript SEO, you’ve probably seen several.
A link which is unrecognisable as a link does not exist for Google's purposes of assigning PageRank. These formats can then be used to sculpt PageRank.
Every time you see a discussion over what is and isn’t an appropriate link format, you have an opportunity for successful PageRank sculpting. Max Cyrek’s post on SearchEngineLand is very illuminating if you are considering this approach.

As an aside – flipping this idea again, a link that cannot actually be interacted with by a user will still be assigned PageRank. For example, attaching href values to the labels of a faceted navigation, even though the clicking on the labels results in product filtering on the current page, rather than a link.
Interaction
Instead of obfuscating your unwanted links, you can have their appearance trigger on interactions Googlebot will not make. Since Googlebot will never encounter these links in ordinary activity, they will not exist.
Here are some ideas you can to test combinations of:
- When a user scrolls, because Googlebot prefers a very large viewport to scrolling.
- When a user moves the mouse pointer / touches over something.
- When a user actually interacts with a link
If you assume that Google is calculating PageRank based on an “initial state” of a URL, it makes sense that “dynamic content that should really be static” can be used to sculpt PageRank. The length of this “initial state” will of course vary visit to visit, and Google is trying to render when the page is “done” for the user. You can’t reasonably out-wait that, but you can show things to all users once they have made ordinary user interactions.
What I do want to emphasise here is that poorly formatted links and interaction triggers will result in a huge accessibility hit, which means you aren’t being a great citizen of the web if you employ them.
Dynamic Rendering
However, if you use dynamic rendering, the pages do not have to 100% accurately reflect the user experience. You also don’t have an accessibility hit to worry about.
Most websites doing any form of of pre-rendering do not have anything approaching 100% accuracy. This is not intentional, it can just be difficult to configure, even with commercial pre-rendering services.
For each link or feature you can ask “does Google really need to see this”:
- Those links you nofollow because of reasons™
- Those links to dynamically generated subcategories inserted by that plugin the CMO was sold on even though they are converting like shit and competing with actual pages.
- All those parameters being inserted on the internal links for “tracking purposes”.
I think as long as you aren’t injecting keyword rich content here, you will be surprised what you can get away with. I think Google offers a tremendous deal of leeway to these sorts of modifications.
How Do You Tell if This is Working?
What’s nice about this approach is that all the tools that simulate Internal PageRank seem to cater to it directly. Things Googlebot does not assess as links, these tools tend not to either. This means that you can still do a before-after comparison for your changes or proposed changed to ensure you haven’t screwed it up.
You can use Search Console’s Inspect URL feature to determine that Google is at least getting the intended HTML.
The other idea to embrace is:
We can never really know whether a link is being used in a PageRank calculation, but we can know when a URL hasn’t been crawled for some time. I think this is the best we can get with this sort of approach.
So, as is often the answer: look at your logs. You can even temporarily place a novel tracking parameter on the user facing links you are hiding to determine if Googlebot is still encountering them. If they are, it doesn’t work. If they aren’t, it might be working (for now).
The Downsides
The main drawback with most of the methods raised in this post if you aren’t being blatant is not “getting caught and penalised“, but keeping that knowledge institutionally.
This is all very much having your cake and eating it, except you now need to remember this particular cake for the rest of your life. Clients I consider very advanced at SEO will occasionally lose track of their setup and have to spend too much time troubleshooting as a result.
The other aspect is that Google should catch onto some of these techniques as it improves, and it will not be obvious (see above). You need to be OK living with this doubt.
I think this whole approach best thought of as introducing fragility into a system in order to eke out a little more performance:
Most of the time, it is not worth it.

This is a good place to end the post.
Thanks for reading.
It is OK to Hide Things, Sometimes
Welcome back.
I’m no longer talking about PageRank Sculpting – this was originally a separate post but the crossover is quite high. We’re talking about using the same attitude but for things, rather than links.
The Cheapest Cloak – Robots.txt
If there is some client side javascript you don’t want Googlebot to execute, then block it in robots.txt:
User-Agent: *
Disallow: /geo-ip.js
That’s it, that’s the idea.
Many websites doing geo-ip redirects of any kind are taking a more direct approach than this method (client side JS, with the script not executing if the UA contains Googlebot), and have been doing this successfully for several years.
Unlike other methods, a robots.txt restriction doesn’t single out any user-agents of IP ranges directly.
If all you have a is a monolithic /scripts.js file to work with, then you will need to extract /feature-i-do-not-like.js into a separate file. Similarly, if you have an inline script that changes things in a way you would prefer not to be seen by search engines – move this to a file and block it.
I don’t actually think this geo-ip usage is a terrible thing (even if it could count as a sneaky redirect). It allows all versions of the website to be indexed, and sends a user to the correct location on first landing. If you strongly enforce geo-ip redirection (“you can never visit {website}.com, peasant”) then please stop.
I’m also saying that as a consultant, politically, you do not have to make a stand regarding GEO-IP redirects for SEO reasons. There are good UX reasons for someone to make this stand.
This method has the benefit of not singling out a single user-agent, or involving IP detection (in the cloak). Instead it exploits the law-like approach (rightly so) Google has toward robots.txt.
Isn’t robots.txt cloaking incredibly risky?
Yes and no.
Abstractly, Googlebot is presented with a dilemma:

But there’s only one way this dilemma can reasonably go:
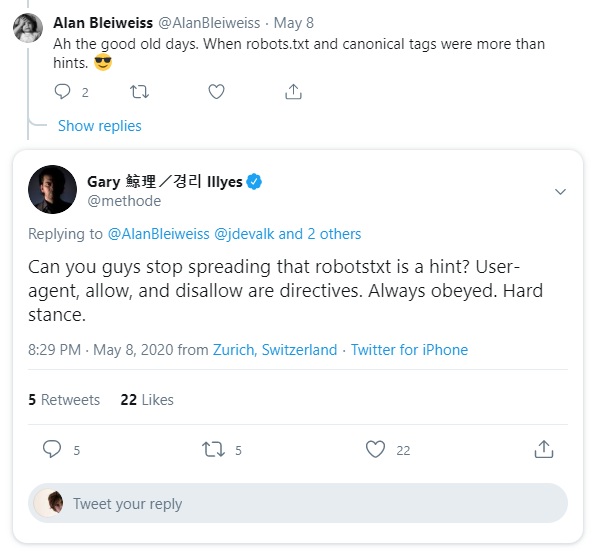
If you are reading this blog post, you can probably determine via access logs whether this statement is true. We can determine whether Googlebot has accessed a script. As before, we can add unique tracking parameters to our scripts to aid this process (and additionally rename them).
(As another aside, other teams at Google use “Googlebot”. If it’s humans, then I think it’s likely that they will disobey robots.txt).
Anything Else?
There isn’t really a limit – as the whole idea is “did you know you can hide things?”
One recurring worry is Intrusive Interstitials. You can prevent the interstitial from being crawled. By whatever method.
I was reading Rachel Costello‘s post on A/B & Multivariate Testing this morning, and which raised the concern around cloaking. I’m 100% OK with search engines not seeing A/B tests performed on the same URLs. I’ve not yet seen any issues with preventing Search Engine crawlers from being exposed to (same URL) tests, and would love to hear from anyone that has.
If the A/B tests are done on separate URLs via client side redirects, again I’m very comfortable with blocking the script that governs the redirect.
This can escalate quickly – don’t like the faceted navigation? Don’t load it.
Isn’t This All Cloaking Though?
Sure, why not. Don’t do it.
You should not do this for a client that does not understand the risks.

“Client Side Progressive Enhancement and Personalisation” is not for everyone.
I think the following questions approximate how I think about this:
- Is the same content exposed to humans and users?
- Does it look like hacked site cloaking?
- Would a canonical pass between two versions?
- Would it pass manual review?
- Would it get the benefit of the doubt if they noticed it?
- How “active” is the detection method? Does it rely on user-agents or features Googlebot can’t or won’t use?
Google absolutely cannot publicly recommend actions which are working in practice and have passed manual review, because the likelihood for self harm is sky high, even though they might agree that “yes, in this particular incidence then what you want to do is fine, but generally it is not”.
Consider how over-analysed and misinterpreted their tweets are. They can’t say “yeah we don’t care if you remove the newsletter link for Googlebot, seems like a waste of time though.”
This is all a waste of time.
I was exposed to many of these ideas in this post by working with differenet clients, and encountering happy accidents of misconfigurations that “work”. For this reason I would recommend holding back on the initial consulting instinct of “this is broken” whenever reviewing something misconfigured, you might learn something cool.
Thanks for reading!
Some Presentation Slides:




I’d like to re-emphasise the final slide.

If you’ve read this far, tweet the damn post.
I’m doing this on Monday.