
Prerequisite reading – Breaking the Head Quietly. tl;dr invalid tags in <head> terminate the head, moving those elements into the <body>, where they become invalid.
The issue with the <noscript> head break is that:
- It’s quiet.
- It’s quite difficult to assess the impact once you do spot it.
This post doesn’t change either of these things; it’s still a bad idea to rely on Googlebot to make decisions about whether it’s worth rendering your content.
(You aren’t going to like what it decides)
But it should give you some food for thought about “render budget”, and why you should sidestep it.
This post is only possible because our tooling is better than when I covered this in 2017. The URL Inspection tool launched in 2018. We got the URL Inspection API earlier this year (2022).
Scenario
For this client, the product page template contained the classic Noscript GTM iframe issue.
Unusually for this issue, this was near the opening of the <head>, meaning were Googlebot to attempt to assess a page without JS enabled, the <head> would be empty.
This could be replicated in the browser by disabling JS.
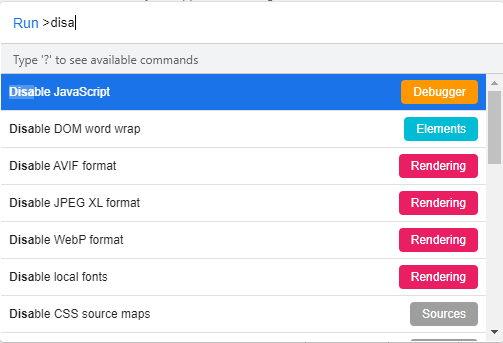
But what was Googlebot seeing?
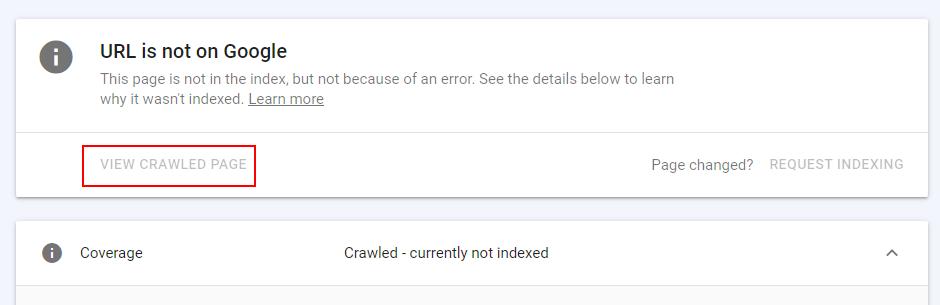
The URL inspection Tool for ‘Crawled, currently not indexed‘ URLs will not return any HTML.
You cannot ‘View Crawled Page‘, so you cannot see what Googlebot did or did not render:
But sometimes you may see a sliver of it:
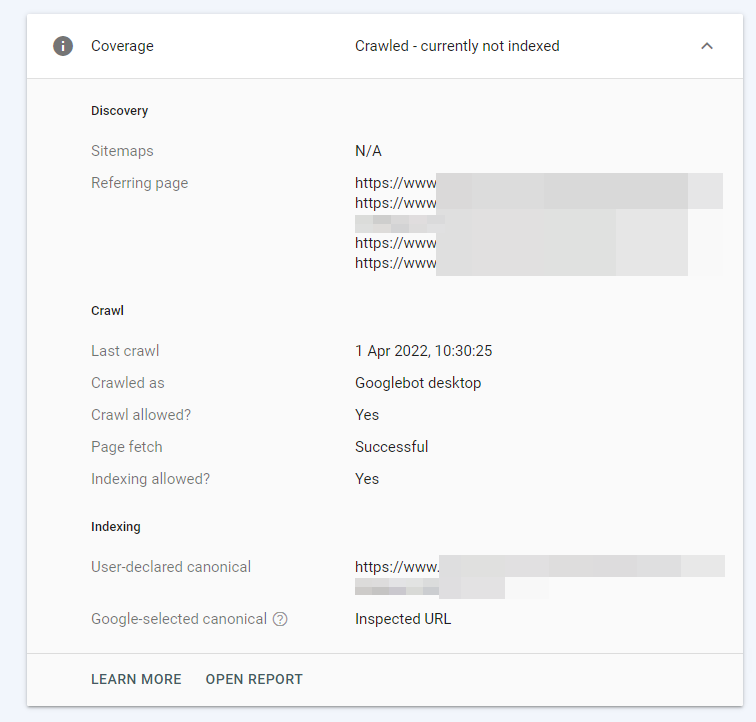
While the rendered DOM is not available, the User-declared canonical is sometimes recorded for pages which are Crawled, not currently indexed, when there is a noscript-head break present:
This is the only part of this post worth remembering. I spotted this by accident, because of the unusual circumstances. Apparently it's quite rare. For the skim readers: Search Console will record the User-declared canonical for pages which are not indexed.
The Client’s Issue
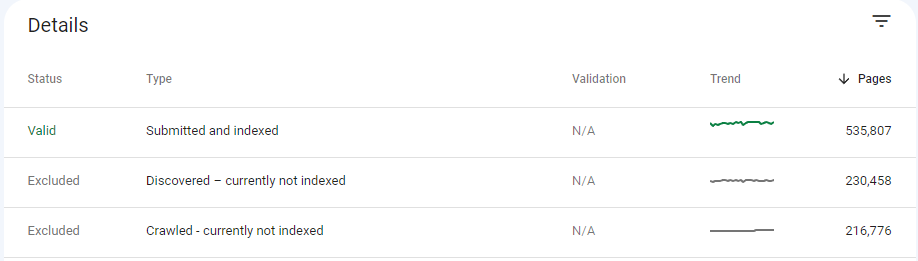
Search Console’s sample of the 1k latest Submitted and indexed pages contained 999 product URLs. Running these through the API, we can see that 995 of these have ‘User-declared canonical‘ values.
The 4 that didn’t? API timeouts. On retry they had values.
The Search Console sample of Crawled, currently not indexed contained 625 product URLs. Of these, 12 returned ‘User-declared canonical‘ values.
Very few.
For these requests, several directives were now outside the head and ineligible for consideration. I’m interested in this case because, for this client, there are ~217k URLs with this crawled-and-rejected status:
We know this product template HTML always has a canonical.
And we know that this canonical is only valid when JavaScript is enabled.
From this we can infer that Google is only able to record the canonical link element when it’s present in the <head>, which is to say when it’s rendering with JavaScript.
So far, every one of the indexed product pages has a recorded canonical, indicating JS was being used. When Googlebot fully-renders the page, the templated elements are usually sufficient for the page to be indexed.
But when Googlebot does not render the page with JavaScript enabled, every <head>-only directive is missing (e.g. title, hreflang, canonical, robots). This accordingly lowers the “quality” of the page substantially enough that the page is not a reasonable candidate for indexing.
My thinking is that the 12 recorded canonicals under Crawled, currently not indexed represent pages where Googlebot actually did execute JavaScript, but the quality/PageRank was not sufficient for the page to be indexed.
For the other 613 which were crawled, but did not warrant a canonical being returned in Search Console, I am inclined to believe an attempt to render with JS was not made.
Off this back of this, Google has assessed them as insufficient for indexing, while we’d probably hold that their index status should be indeterminate (pending, you know, an actual render).
For the client, this difference matters. If we take this on face value and act as if these pages are of insufficient quality for indexing, we will spend our (their) resources poorly.
Let's keep in mind that there's a good chance I'm wrong here, and that Search Console merely has issues returning the recorded canonical, and fixing this will do nothing for the proportion of indexed pages. We'll see!
How Could We Think About This?
The original temptation (for me) is to look at these and think “well, Google is currently indexing hundreds of thousands of these products just fine. It’s either links (PageRank) or content impacting this batch, let’s fix those”.
And you’d be right. Either of those levers would work here:
Bryce: [Snort, Cough, Sniff] Oh, God! It’s a fucking milligram of sweetener. I wanna get high off this, not sprinkle it on my fucking oatmeal.
Bateman: It’s definitely weak, but I have a feeling that if we do enough of it, we’ll be ok.
American Psycho (2000)
But they may not be the most efficient levers to pull:
Does This Change How We Work?
It doesn’t.
We already know how to fix this; move that GTM implementation to the final line of the <head> if it has to be there, so the head can die gracefully, or put it in the opening of the body like the documentation tells you.
SEO isn’t hard. You really shouldn’t sweat the minutiae. Except when you should.
Good luck knowing when that is.
Many Thanks
A lot of appreciation goes to Sitebulb for automatically spotting this in the sample crawl of the domain.
Then an exactly equal amount of appreciation goes to Screaming Frog for letting me paste stuff into list mode to get the URL Inspection API results faster.
Shoutout to Google for not making a Crawled, currently not rendered categorisation yet.