
There are many HTML tags which search engines will only trust when they are within the <head> because that’s where they belong, and it’s generally too easy to inject HTML into a body to trust them if they were there. These are tags such as:
- <link rel=”canonical”>
- <meta name=”robots”>
- <link rel=”alternate”> (both mobile and hreflang alternates)
- <link rel=”amphtml”>
- Site verification tags for GSC.
- Obviously some others.
Imagine you’re Googlebot.
You’re going about your day crawling the web. You’ve found a new page and go about downloading and parsing the HTML head of a webpage. You’re minding your own business when out of nowhere someone throws an <iframe> tag at you. What do you do in this situation? The </head> is nowhere in sight, and yet there’s an <iframe> in the middle of meta keywords country.
You could pretend that you didn’t see the iframe and assume that you’re still in the page head, but what if the page body started and no one thought to tell you? You don’t want to be extracting critical tags like canonical or robots from the body. What if someone has maliciously injected a noindex tag there?
So you decide that no, you won’t let this page take you on that emotional rollercoaster. You decide that when that <iframe> appeared, the header finished. This is the least bad way in which browser vendors have decided to handle the HTML spec. Browsers do this, and so does Googlebot.
The situation where body-HTML tags appear in the <head> is more common than you think, and your carefully crafted robots directives are being ignored because of it. To be clear, the only HTML tags that should appear in the HTML <head> are:
- <title>
- <style>
- <base>
- <link>
- <meta>
- <script>
- <noscript>
- Something I’ve forgotten.
Anything else will terminate your head prematurely.
You might be thinking “What idiot would put an <iframe> in the <head>?”. If you’ve ever ignored the “put this snippet in the head and this snippet in the body” instructions from a tool like Google Tag Manager, then you are that idiot:
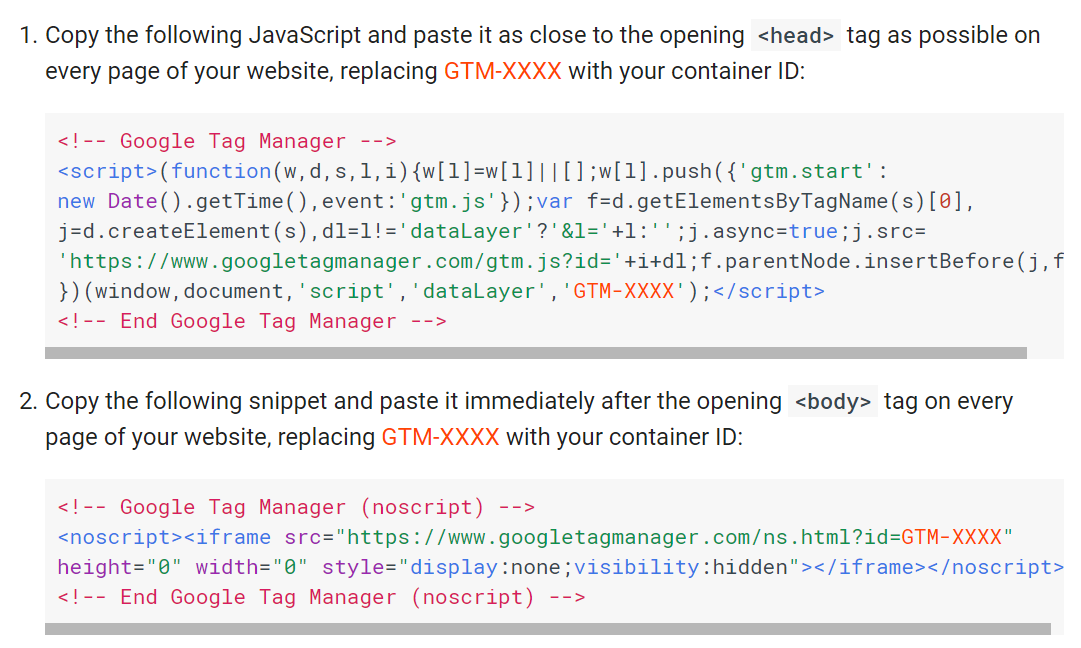
If you’re an SEO for long enough you’ll eventually come across some advice to move something higher in your code, because reasons. This advice seems like nonsense, but many otherwise seemingly intelligent people swear by it, and sometimes offer a smidgen of evidence. Of course, it feels like bullshit when packaged this way (by me):
Inspect Element for SEO
Simply put, you risk any head-only SEO directives being ignored if they appear below non-valid head tags. Moving the tags up gives the head permission to die, but only once it has done what we need. You can look to actually fixing the head as another project (but everyone will think you are a nerd and you’ll get into soul-withering fights with marketing managers).
Ensure the head isn’t broken to ensure your directives in the head are working.
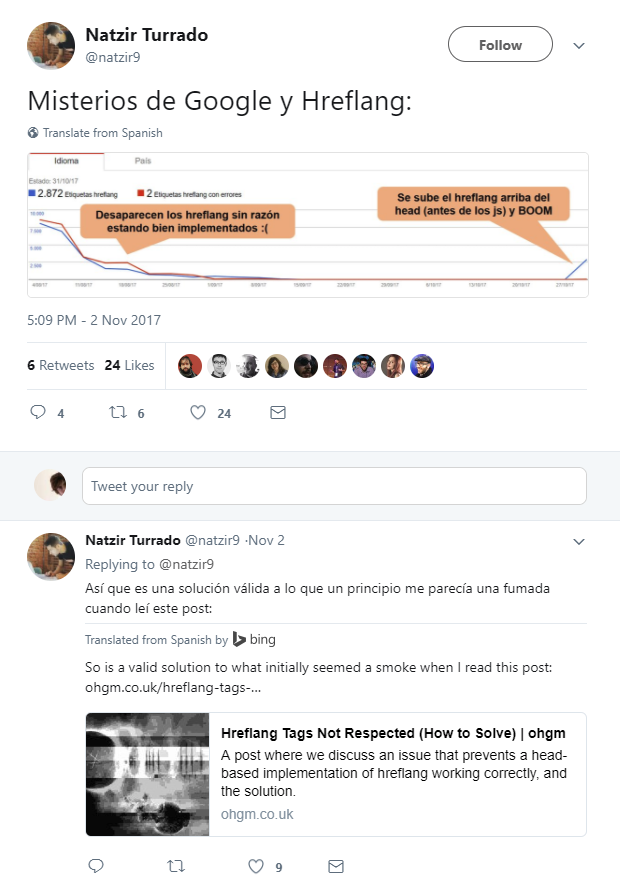
Google have previously mentioned this all before, and it’s fairly widespread knowledge in the SEO community. I saw the slides from Patrick Stox’s pubcon presentation mention this approach. Essentially you must use inspect element to look at the DOM and not view source to make sure the tags in the head are actually in the head:
This was a fair enough statement to make, the post itself wasn’t clear whether we had or not. But to be clear, we did inspect the DOM, and the head wasn’t broken and the tags were all present. The key line from the article was:
“The hreflang implementation was just before the closing tag of the head, and following a <noscript> implementation of GTM.”
And for the crawler, this meant that the head was broken.
The Perils of <noscript>
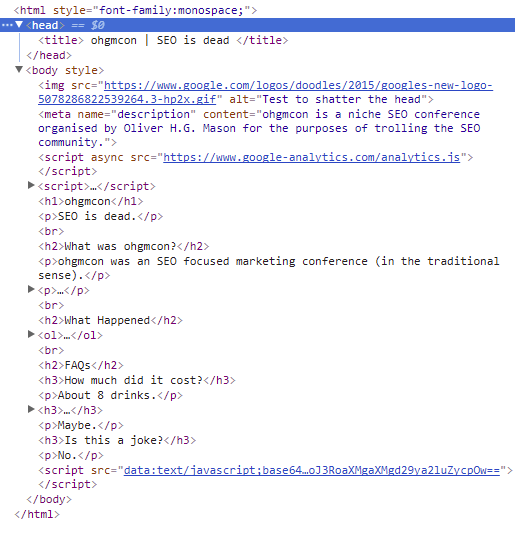
To demonstrate how things can look OK when they aren’t I’ve edited the /con1 page. Inserting an <img> tag in the head results in the browser terminating the head. As a result, the offending tag and every other directive is moved to the body:

However, wrapping that same <img> inside a <noscript> means that the <head> remains intact (it’s not terminated early):
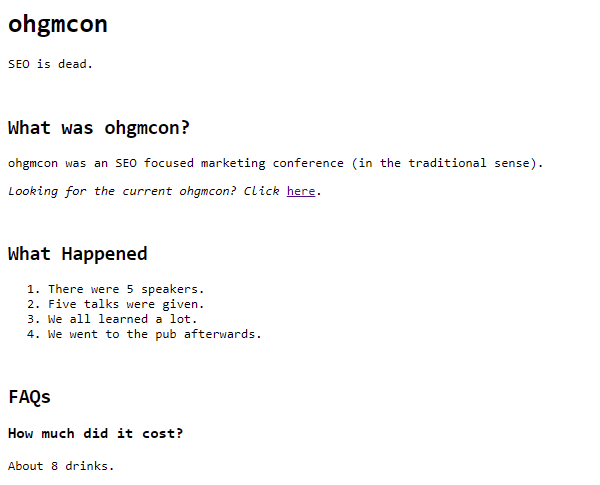
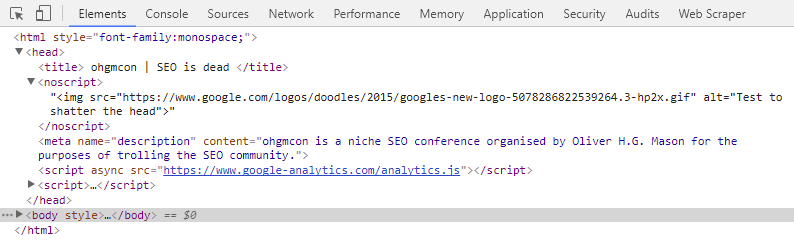
The <noscript> in the head causes my browser to ignore the <img>, so it does not break my browser’s interpretation of the head. The body does not start early. Fetch and Render is of course going to use JavaScript, too:
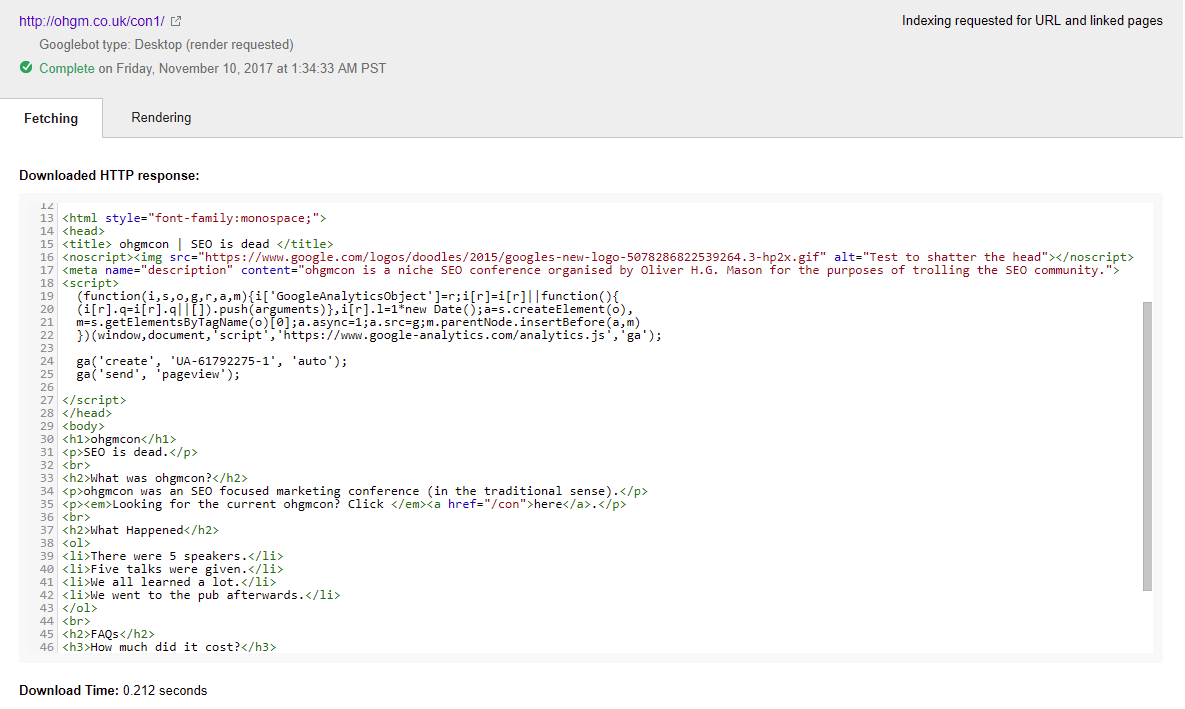

For fetch and render (and the indexer), the head is not broken.
But if I disable JavaScript before examining the DOM, the <head> is once again broken, and the <img> will be interpreted as one:
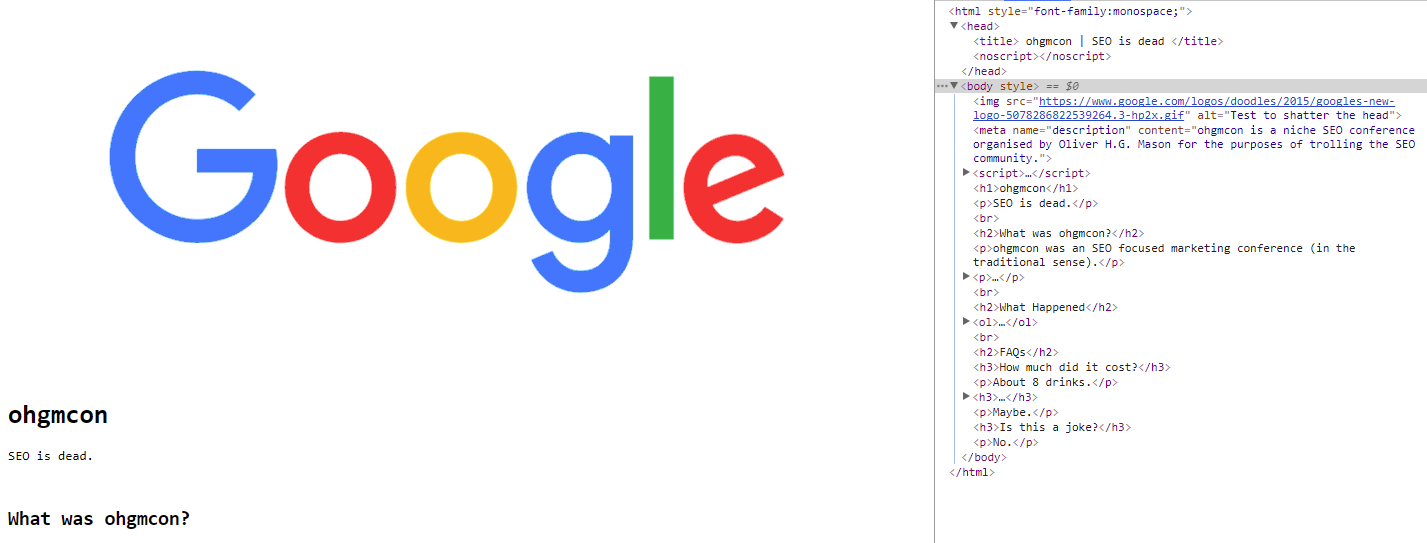
Indicating that when the crawler crawls, the head is broken. But for a cursory inspect element, everything looks fine.
Toggle JavaScript When Inspecting DOM
This should be your key takeaway for handling these edge cases:
If you want to be thorough, also use ‘inspect element’ with JavaScript disabled. Compare the diff.
Or just be really careful with <noscript> tags (and their contents) in the <head>.
When used inside the <head> element: <noscript> must contain only <link>, <style>, and <meta> elements.
This additional check should augment your standard “run a diff check on viewsource and inspect element“. If a directive which should work isn’t working, it might be because of this.
We can see at least that the brand-new-meta-description is working with this head-broken-with-JS-disabled approach:

I find this so interesting because it runs counter to my own mental model (Crawler crawls, Indexer renders) and recent posts on the subject basically confirming this model (Google cares about the rendered HTML for hreflang).
But is also feeds into deeply held suspicions regarding lazy-we-dont-need-a-full-render-indexing. Surely the full bells-and-whistles indexer should have picked up my client’s hreflang tags in the previous article? I don’t buy that Googlebot would feed the indexer non-js rendered HTML, but I do buy that some cost cutting might result in that behaviour for some sites. Assuming full render always may be imprudent.
I also might be completely wrong.
Taking This Further
If the <noscript> + <body-only> combo allows you to reliably break the head for the crawler and not the indexer, and GTM lets you add whatever you want later, you may be able to diagnose which directives are being obeyed and when.
Have fun.
Hey Oliver, I know this is an older article but I feel like it needs a little update.
DeepCrawl are linking here from their article about breaking head (https://www.deepcrawl.com/knowledge/guides/rendering-issue-metrics/) and they are interpreting the rendered DOM as if it was broken just because there’s an html tag other than metadata content (https://www.w3.org/TR/html53/dom.html#metadata-content-2) in there.
However, my testing shows that you can only break the within the HTML source.
Injecting tags into with JS does not break it because it was already correctly interpreted (I’m sure chromium source code would confirm this but I can’t find the relevant part).
This can easily be checked by injecting something into the and checking where and are, as opposed to inserting it into the HTML source code.
Sample jQuery snippet one can use:
$(“).insertBefore(`title`);
I’d appreciate if you could update this article if you find this tidbit useful. It could also help make some SEO tools better, as currently said DeepCrawl is not behaving correctly flagging false positives.