
There are plenty of SEO reasons you might want to look at http headers. Google love offering them as an alternative implementation for a number of directives, including:
- Vary: User-Agent
- Canonical
- Hreflang Implementation
- X-Robots (noindex, nofollow)
Link: <http://es.example.com/>; rel="alternate"; hreflang="es"
Link: <http://www.example.com/>; rel="canonical"
X-Robots-Tag: googlebot: nofollow
Vary: User-AgentIf anyone’s doing anything a little sneaky, you can sometimes spot it in the file headers.
There are a number of tools that let you inspect single headers, including your browser (press F12 and poke about to get something like the following).
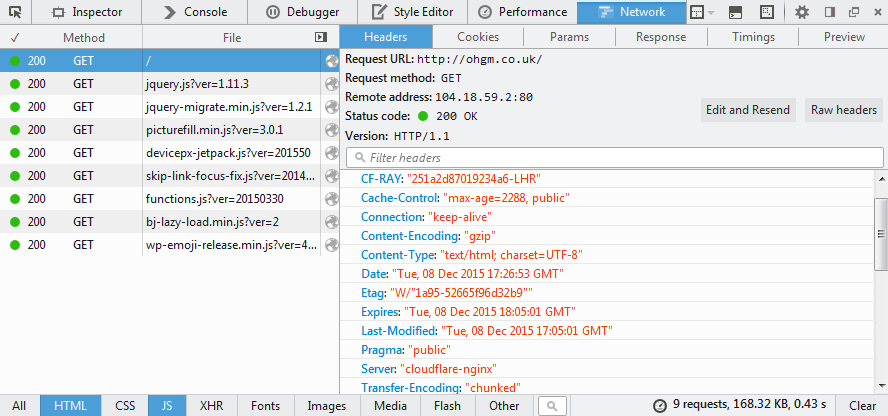
When you need to check which pages on a domain aren’t returning the correct hreflang headers, this method shows its limitations. Very few tools make it easy to gather this for a massive list of URLs (mostly due to having limits). I’ve needed to do this a few times, so I’m sharing the method here in hopes of saving some of you some time.

It’s a Ruby script. It writes the output of a series of the host system’s “curl -I” requests to a csv file. It is not the best way to do things, but it works. I’ve tested this on Mac, Ubuntu Linux, and Windows.
headers.rb
require 'csv'
File.readlines("urls.txt").each do |line|
print line
CSV.open("headers.csv", "a") do |csv|
csv << ["#{line.strip}", `curl -Is #{line.strip}`]
end
end
puts "All headers written to headers.csv"
puts "\nHit enter to exit"
getsSetup
- Download the script.
- For Mac and Linux users, this should just work. Windows users will need to first install GNU on Windows and Ruby.
Usage
- Navigate to the directory containing headers.rb.
- Place a plaintext file containing the URLs for inspection titled ‘urls’ in the same directory.
- Open a terminal and execute the script (windows users may b.e able to double click):
$ ruby headers.rb
The curl output you see in your terminal will be fed line-by-line into an headers.csv file. If one already exists, the additional URLs will be appended:
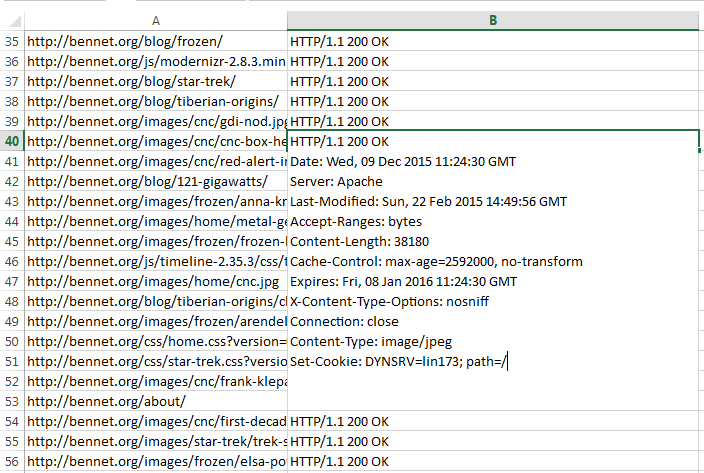
By default this is going to write the entire output to a single cell in csv format, next to the request URL. This can be filtered in Excel, or by editing the script to pipe curl to grep:
`curl -Is #{line.strip}|grep 'thing-to-match'`This will result in smaller csv files, should that be important.
Alternatively
Check out Headmaster SEO, it’s what I now use instead.
Have fun.
Hey there
Tried your script, but it only scrapes information about the first entry in my urls.txt The terminal log goes over all the sites, but the generated export shows only the first one. Any idea how I can fix this? *I’m a noob when it comes to technical things.
The script doesn’t check https urls
Thanks, the -‘k’ flag can be added to curl to skip checking certs, so:
csv << ["#{line.strip}", `curl -Isk #{line.strip}`]I use HeadmasterSEO instead of this now, though.